

La comunità del Natural Language Processing (NLP) è da tempo in fermento grazie al successo riscosso da ChatGPT, Transformers e Large Language Models. Questo tipo di approcci sono estremamente complessi e costosi da replicare, e verranno prossimamente descritti nella rubrica “Alla scoperta dell’Intelligenza Artificiale” di Red Hot Cyber!
Tuttavia, in questi giorni, i professionisti e ricercatori in campo NLP sono stati scossi da un nuovo lavoro pubblicato dalla Association for Computational Linguistics e disponibile in ACL Anthology.

Il paper discute un approccio per la classificazione del testo che utilizza una tecnica molto semplice ma con risultati sorprendenti! Di fatto, l’approccio proposto si basa sulla compressione del testo attraverso gzip (esatto, la stessa compressione che viene usata per comuni archivi di file!) e la più semplice tecnica di classificazione, l’algoritmo kNN (k-Nearest-Neighbor).
Ma vediamo più in dettaglio l’approccio e perché sta riscuotendo attenzione nel mondo AI!
La classificazione del testo è un problema molto intuitivo: data una descrizione, un tweet o una qualsiasi sequenza di frasi, si vuole associare ad essi una classe, ovvero una categoria di appartenenza. Ad esempio, in un problema di categorizzazione di notizie, si vuole associare ad ogni articolo un tag, come “cronaca”, “politica” o “sport”.
Nella sentiment-analysis su social network si potrebbe essere interessati a discriminare i post che trasmettono un pensiero positivo da quelli negativi. Anche per le la posta elettronica, componenti di filtri anti-spam sono spesso basati su classificatori di testo.
Attualmente, le tecniche più performanti di classificazione del testo si basano su reti neurali profonde (Deep Neural Networks, DNN), modelli che apprendono come classificare attraverso molti testi forniti in un insieme di dati chiamato training-set.
Tra le architetture più diffuse c’è BERT (Bidirectional Encoder Representations from Transformers), una rete neurale sviluppata da Google basata su Transformers. L’addestramento di queste reti ha l’obiettivo di ottimizzare centinaia di milioni di parametri attraverso l’utilizzo di enormi insiemi di testi. Questi addestramenti sono molto costosi computazionalmente e non sono alla portata di tutti.
Il lavoro recentemente pubblicato non richiede una fase di addestramento e si è dimostrato migliore dei modelli allo stato dell’arte per il problema di classificazione, con un giusto bilanciamento tra efficacia e semplicità.

La semplicità dell’algoritmo proposto si basa su gzip, un compressore loss-less di dati, una misura di distanza e un classificatore kNN. L’idea è utilizzare il compressore per individuare i pattern regolari nel testo e tradurli in punteggi di similarità utilizzando la metrica di distanza.
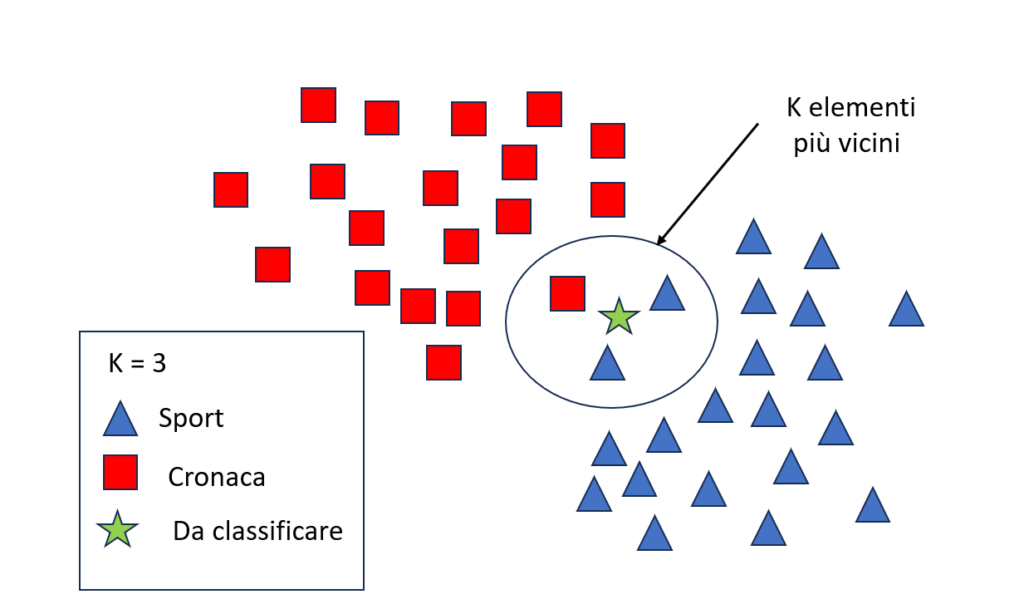
Questi punteggi vengono quindi utilizzati per classificare il testo con l’algoritmo kNN, che assegna un nuovo testo ad una classe basandosi sui K testi più vicini nel set di addestramento, come si può vedere nell’immagine seguente.
In questo esempio, il nuovo elemento da classificare è assegnato alla classe sport, dato che tra i 3 elementi più vicini è la classe maggiormente rappresentata. Come si può intuire, il kNN è tra gli algoritmi più semplici del Machine Learning. Questo algoritmo, inoltre, non ha bisogno di una vera fase di addestramento.
La semplicità del metodo proposto ha stupito gli esperti di NLP. L’algoritmo ideato è implementabile attraverso sole 14 righe di codice in Python, come mostrato di seguito.

Il metodo è stato testato su diversi set di dati, mostrando performance migliori rispetto reti neurali allo stato dell’arte, superando anche BERT su alcuni dataset. Si dimostra anche eccellente quando c’è solo una piccola quantità di dati etichettati disponibili.
La comunità è in fermento per questo lavoro innovativo, i cui risultati suscitano grande interesse e certamente saranno oggetto di approfondimenti nei prossimi mesi.
L’importante lezione che possiamo trarre è che ogni problema ha la sua soluzione. Spesso, soprattutto nell’intelligenza artificiale, i problemi più semplici possono trarre enormi vantaggi da soluzioni altrettanto semplici.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/