



Autore: Edoardo Bavaro
Data Pubblicazione: 02/06/2022
Nel corso degli anni, le tecnologie di cifratura dei dati sono andate in contro ad innumerevoli evoluzioni, le nuove tecnologie hanno surclassato quelle obsolete, come è sfortunatamente accaduto all’algoritmo SHA-1. Partiamo dal principio e comprendiamo cos’è SHA-1 e quindi in generale, cos’è una funzione di hash.
La funzione di hash non fa altro che produrre, partendo da un input (es: stringa a) di lunghezza indefinita, un nuovo input (es: stringa b) di lunghezza definita, che non dipende dalle dimensioni dell’input iniziale.
Un esempio pratico con due funzioni di hash molto conosciute MD5 e SHA-256:
Stringa: ciao
Risultato in MD5: 6e6bc4e49dd477ebc98ef4046c067b5f
Risultato in SHA-256: b133a0c0e9bee3be20163d2ad31d6248db292aa6dcb1ee087a2aa50e0fc75ae2
Qualunque sia la dimensione della stringa in entrata non influenzerà la lunghezza della stringa in uscita, che sarà di 32 caratteri per MD5 e 64 caratteri per SHA-256.
Per definizione, il risultato ottenuto da una funzione di hash non è reversibile, quindi partendo da questo non è possibile ottenere l’input iniziale.
Un’altra caratteristica è che l’input finale ottenuto è unico, ovvero non possono esistere due o più stringhe iniziali che generano lo stesso input finale. Queste due caratteristiche insieme, rendono gli algoritmi di hash ottimi per il salvataggio di password in database o per verificare l’integrità e autenticità di un file, poiché se un file sarà stato manomesso da qualcuno, l’algoritmo genererà un risultato che non combacerà con il risultato originale.
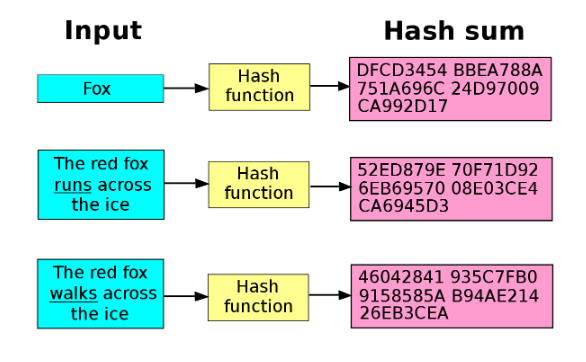
Esistono moltissimi algoritmi di hash e la loro sicurezza si basa su quanto è bassa la probabilità di ottenere una collisione.
Una collisione consiste in due o più input diversi che generano lo stesso output finale.
Non abbiamo detto che la stringa ottenuta da un algoritmo di hash è unica? Essendo la stringa ottenuta di dimensione fissa, risulta difficile pensare che non vi possano essere più input, magari anche di dimensioni molto diverse tra di loro, che non possano generare la stessa stringa di output.
La probabilità è matematicamente improbabile, poiché si tratterebbe di analizzare un numero indefinito di variabili, ma non impossibile. Quindi da questo si deduce che un algoritmo che genera molti caratteri è più sicuro di uno che ne genera di meno, poiché ha meno possibilità di generare una stringa uguale per valori iniziali differenti.

Dopo una breve introduzione agli algoritmi di hash, andiamo ad analizzare SHA-1 e la collisione che l’ha mandato in “pensione”.
SHA-1 è un algoritmo che genera una stringa di 40 caratteri esadecimali. Pubblicato per la prima volta nel 1995 è stato pian piano messo da parte per far spazio a nuovi algoritmi con una source più sicura e con digest (stringa finale) più lungo.
Uno dei primi a mettere in discussione l’affidabilità di SHA-1 è stato Marc Stevens che, tramite attacco (ricerca di hash uguali all’interno file diversi), ha ottenuto 261 , circa 9.000.000.000 miliardi, di operazioni SHA-1. Questo attacco è alle fondamenta dello studio effettuato da Google.
Nel 2017 Google, con l’ausilio dello stesso Marc e di altri crittografi, ha generato una collisione, in seguito denominata SHAttered, che ha messo definitivamente la parola fine all’algoritmo SHA-1.
L’azienda è riuscita a generare due file pdf diversi aventi lo stesso SHA-1. Analizzando i due file si nota che differiscono tra di loro solo di pochi byte, ma nonostante questo l’attacco ha richiesto una quantità computazionale incredibile, come descritto nel paper ufficiale dello studio.


Ricordiamo che la maggior parte dei virus è trasmessa tramite file, in aggiunta a questo c’è la possibilità di manomettere lo SHA-1 e quindi di ottenere un file malevolo non distinguibile dall’originale se non tramite la verifica di altri algoritmi.
Questo ha spinto molte aziende, tra le quali troviamo anche Microsoft ad abbandonare definitivamente l’algoritmo SHA-1.
Nonostante attualmente sia difficile replicare una collisione come SHAttered, per via della potenza computazionale da utilizzare, nonché una manomissione del codice dei file, è sempre consigliato verificare tramite diversi algoritmi di hash l’integrità dei file, infatti, prendendo sempre il caso SHAttered, nei due file coincide solo SHA-1 e non altri algoritmi come lo SHA-256.


Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione