



Alcuni di voi possono pensare che la data science e la cybersecurity siano due mondi separati, ma in realtà esistono interconnessioni significative tra le due discipline.
Dalla nascita del MLaaS, Machine Learning as a service, è diventato di fondamentale importanza capire i problemi che i modelli di Machine Learning possono comportare a livello di privacy e sicurezza.
Uno dei problemi più studiati è quello del Model Inversion Attack, che è un tipo di attacco in cui si cerca di inferire le informazioni riguardo un sogetto usando l’output di un modello di Machine Learning che questo ha usato.
In questo articolo però vorrei porre la vostra attenzione a un caso ancora più specifico per introdurvi quello che viene chiamato Hidden Learning.
Immaginate di essere uno user, e di volerlo utilizzare una Neural Network fornitavi da una compagnia. Voi utilizzerete la rete dandogli in input dei dati sensibili per ricevere un output. Magari state usando un’app che crea un avatar da una vostra foto per esempio.
Siccome prima di usare l’app avete letto policy riguardo la privacy, siete certi però che la compagnia puo accedere esclusivamente all’output della rete e non alla vostra foto in input, quindi i vostri dati sensibili sono al sicuro. Ma in realtà, questo non vuol dire che la compagnia non possa utilizzare l’output per inferire qualche informazione sul vostro input. Questo potrebbe essere possibile se la compagnia ha utilizzato l’Hidden Learning.
Mettiamoci adesso dal lato dell’attaccante, quindi nel caso precedente dal lato della compagnia. Quello che facciamo è di creare una rete ufficiale No che effettivamente risolva il task ufficiale To che gli user si aspettano, ma nello stesso momento creiamo una rete segreta Ns che risolve un altro task segreto Ts.
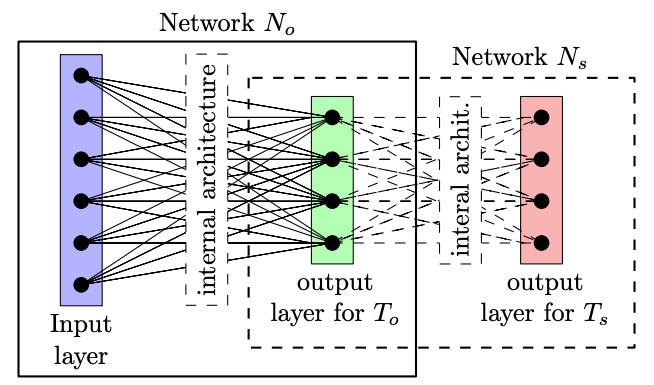
Il modello sarà trainato in contemporanea facendo una combinazione dell’output del task ufficiale e del task segreto, questa combinazione potrebbe essere banalmente la somma delle loss. Quindi la rete imparerà in contemporanea a risolvere entrambi i task.
Questa rete non desterà sospetti perché il modello avrà una grande performance sul task ufficiale, quasi stato dell’arte, non ci sarà un grande downgrade, ma in più avremo la seconda parte della rete il cui task sarà quello di estrarre dall’output ottenuto di nuovo le informazioni contenute nell’input, un pò come funziona per gli autoencoder.
Immaginate durante un emergenza medica come quella del Covid-19 il governo che chiede ad una compagnia privata di sviluppare un’app che consenta di predire se una persona potrebbe manifestare sintomi gravi. Il codice non è open source e quindi non può essere controllato dalla community.
Se questa compagnia adottaste questo framework, potrebbe risalire a informazioni sensibili come il fatto, se la persona soffriva di malattia cardiovascolari o altro ancora.
L’Hidden Learning è un framework semplice che permette di allenare una rete per risolvere un task segreto. Le performance del task originale vengono degradate non raggiungendo lo state dell’arte ma rimangono comunque molto buone da non destare sospetti.
L’output di una prima rete viene passata ad una seconda rete segreta che ricostruisce le informazioni di partenza. Questo può portare ad un data leackage, ed è un campo in cui si continuerà a fare molta ricerca.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione