



Quando un modello di Machine Learning viene messo in produzione, spesso devono essere soddisfatti requisiti che invece non vengono presi in considerazione nella fase di prototipazione e sviluppo del modello. Ad esempio, in produzione il modello dovrà essere in grado gestire molte richieste da diversi utenti che che utilizzano il servizio. Si vorrà quindi ottimizzare, ad esempio, la latenza e/o il throughput.
Ciò significa che il modello di apprendimento automatico deve essere molto veloce nel fare le sue previsioni, e per questo esistono varie tecniche che servono ad aumentare la velocità di inferenza del modello stesso, in questo articolo vedremo le più importanti.
Esistono tecniche che mirano a rendere i modelli più piccoli, e per questo sono chiamate tecniche di compressione, mentre altre si concentrano sul rendere i modelli più veloci nell’inferenza e quindi rientrano nel campo dell’ottimizzazione dei modelli.
Ma spesso rimpicciolire i modelli aiuta anche la velocità di inferenza, per cui la linea che separa questi due campi di studio è molto labile.
Questo è il primo metodo che vediamo, e ultimamente sta andando molto di moda, infatti recentemente sono usciti molti articoli scientifici a riguardo.
L’idea di base è quella di sostituire le matrici di una rete neurale (le matrici che rappresentano gli strati della rete) con matrici di dimensioni più piccole, anche se sarebbe più corretto parlare di tensori, perché spesso possiamo avere matrici di due o piu dimensioni. In questo modo avremo reti con meno parametri un’inferenza più veloce.
Un caso banale è quello di sostituire le convoluzioni 3×3 con convoluzioni 1×1 in una rete CNN. Tali tecniche sono utilizzate da reti come SqueezeNet. Ispirate da questa tecnica di base, sono stati sviluppati altre metodologie di compressioni per scopi diversi, come ad esempio per consentire il fine-tuning large language models quando si hanno risorse limitate.
Quando si esegue il fune-tuning di un modello preaddestrato per adattarlo ad un downstream task, si deve continuare ad addestrare la rete su tutti i parametri, il che può essere molto costoso.
Il metodo proposto nel paper “Low Rank Adaptation Of Large Language Models”, o LoRA, consiste nel sostituire le matrici del modello originale con coppie di matrici più piccole (utilizzando la decomposizione matriciale). In questo modo, solo queste nuove matrici devono essere ri-addestrate per adattare il modello a piu downstream tasks.
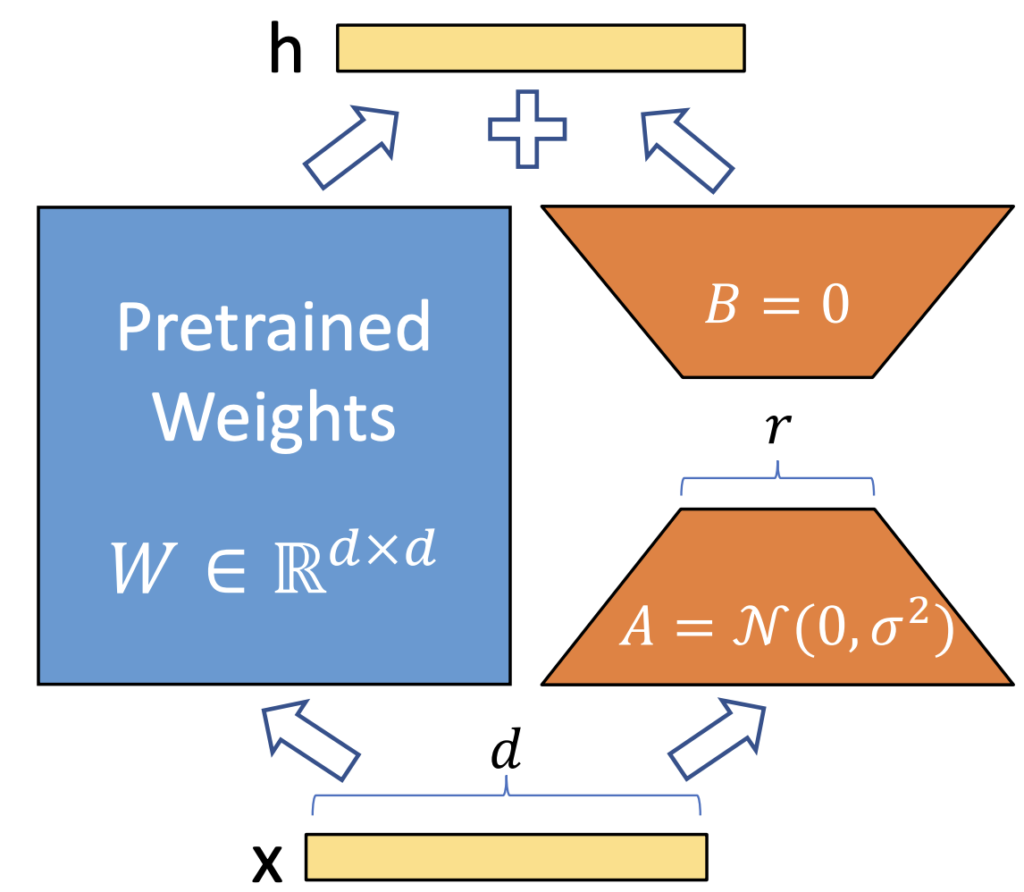
Ad oggi una delle librerie per l’impelementazione di LoRA più utilizzate è PEFT di Hugging Face 🤗.
Questo è un altro metodo che ci permette di mettere in produzione un modello “piccolo” e quindi veloce.
L’idea è quella di avere un modello grande, chiamato teacher (insegnante), e un modello più piccolo, chiamato student (studente), e di utilizzare le conoscenze dell’insegnante per insegnare allo studente cosa prevedere. In questo modo possiamo mettere in produzione solamente lo studente.
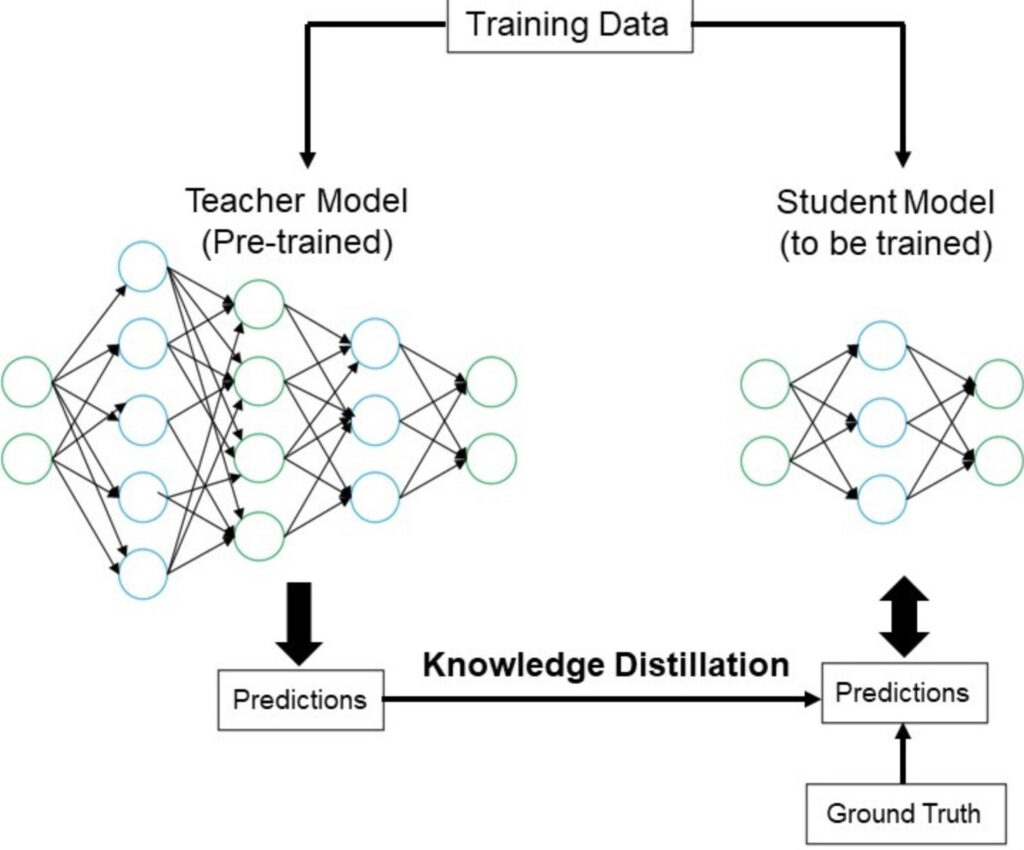
Un classico esempio di modello addestrato in questo modo è DistillBERT, che è il modello per student di un modello più grande chiamato BERT. DistilBERT è più piccolo del 40% rispetto a BERT, ma mantiene il 97% delle capacità di comprensione del linguaggio ed è più veloce del 60% nell’inferenza.
Uno degli svantaggi di questo metodo è che per addestrare lo studente è necessario avere a disposizione il modello techer di grandi dimensioni, e non è detto che si disponga delle risorse necessarie per addestrare un modello del genere.
Un concetto chiave da comprendere nella Knowledge Distillation è la divergenza di Kullback-Leibler, che è un concetto matematico per capire la differenza tra due distribuzioni, e in effetti nel nostro caso vogliamo capire la differenza tra le previsioni dei due modelli, quindi la funzione loss dell’addestramento è basata su questo concetto matematico.
Il pruning è un algoritmo di compressione di reti neurali che ho studiato per la mia tesi di laurea durante il mio tirocinio ad INRIA, infatti ho già pubblicato un articolo tecnico su come implementare il pruning in Julia: Iterative Pruning Methods for Artificial Neural Networks in Julia.
Il pruning è nato per risolvere il problema dell’overfitting negli alberi decisionali (decision trees), infatti i rami venivano tagliati per diminuire la profondità dell’albero. Il concetto è stato successivamente utilizzato nelle reti neurali, in cui vengono rimossi gli archi e/o nodi della rete (a seconda che si esegua un pruning non-strutturato o strutturato).
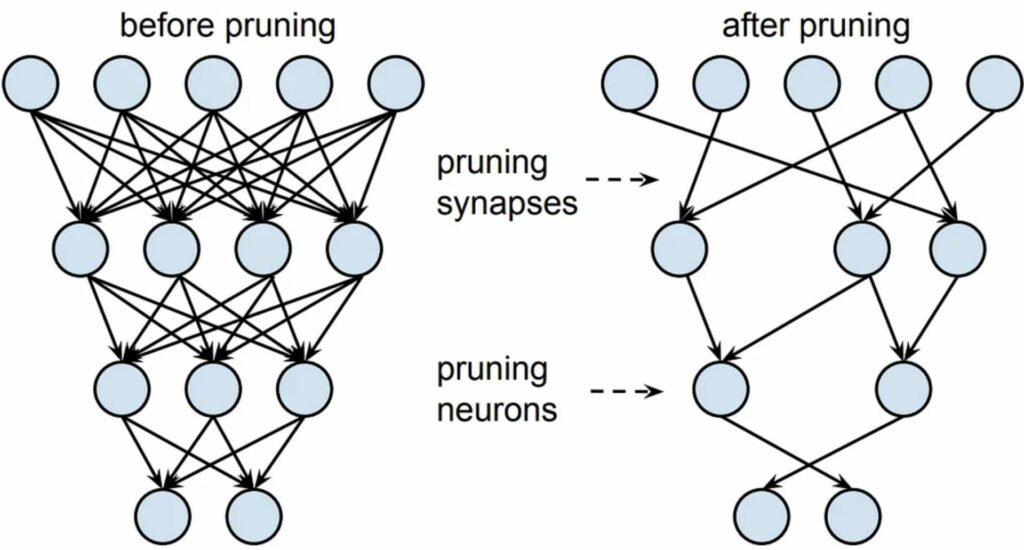
Supponiamo di rimuovere interi nodi dalla rete, le matrici che rappresentano gli strati della rete diventeranno più piccole insieme al modello, e quindi anche la computazione piu veloce.
Al contrario, se rimuoviamo singoli archi, la dimensione delle matrici rimarrà la stessa, ma metteremo degli zeri in corrispondenza degli archi rimossi, e quindi avremo matrici molto sparse. Nel pruning non strutturato, quindi, il vantaggio non sta nell’aumento della velocità, ma nella memoria, perché il salvataggio di matrici sparse in memoria occupa molto meno spazio rispetto a quello di matrici dense.
Ma quali sono i nodi o archi che vogliamo tagliare? Quelli più inutili… Si sta facendo molta ricerca in merito, e vorrei proporvi due paper in particolare se siete interessati a questo argomento:
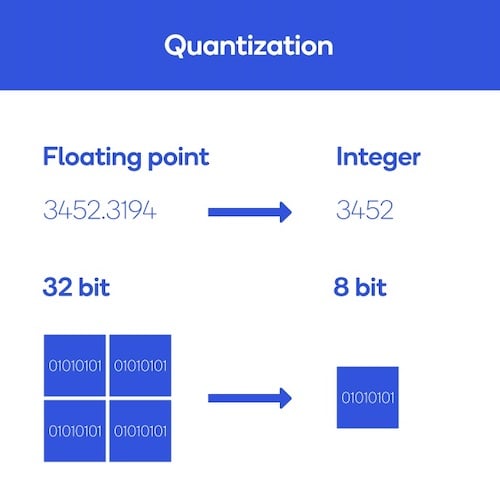
Non credo di sbagliare nel dire che la quantization sia la tecnica di compressione più ampiamente utilizzata al momento. Di nuovo, l’idea di base è semplice. Generalmente rappresentiamo i parametri della nostra rete neurale utilizzando numeri floating point a 32 bit. Ma cosa succederebbe se utilizzassimo numeri con minor precisione? Potremmo utilizzare 16 bit, 8 bit, 4 bit o persino 1 bit e ottenere reti binarie!
Cosa implica ciò? Utilizzando numeri a minor precisione, il modello sarà più leggero e più piccolo, ma perderà anche di accuratezza, fornendo risultati più approssimativi rispetto al modello originale. Questa è una tecnica molto utilizzata quando dobbiamo eseguire il deploy di reti su hardware particolari come gli smartphone, perché ci consente di ridurre notevolmente le dimensioni della rete. Molti framework consentono di applicare facilmente la quantization, come TensorFlow Lite, PyTorch o TensorRT.
Questa tecnica può essere applicata durante la fase di pre-training, in modo da addestrare direttamente una rete i cui parametri possono assumere solo valori in un determinato intervallo, o durante la fase di post-training, in modo da arrotondare i valori dei parametri alla fine dell’addestramento.
In questo articolo, abbiamo esaminato diverse metodologie di compressione di reti neurali al fine di accelerare la fase di inferenza del modello, che può rappresentare un requisito critico per i modelli in produzione. In particolare, ci siamo concentrati su Low Rank Factorization, Knowledge Distillation, Pruning e Quantization, spiegando i concetti di base.
Un caso d’uso a cui sono molto appassionato è l’uso della compressione dei modelli per eseguire il deploy degli stessi su satelliti, che è molto utile soprattutto nel campo dell’osservazione terrestre, ad esempio per consentire al satellite di riconoscere autonomamente quali dati o immagini scartare in modo da non sovraccaricare il traffico quando questi dati vengono poi inviati al ground segment per l’analisi dei dati. Spero che questo articolo ti sia stato utile per comprendere meglio questo argomento.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione