



Gli esperti di Palo Alto Networks hanno condotto un esperimento e hanno riferito che i modelli linguistici di grandi dimensioni (LLM) possono essere utilizzati per generare in modo massiccio nuove varianti di codice JavaScript dannoso, che alla fine consente al malware di eludere meglio il rilevamento.
“Mentre gli LLM sono difficili da creare malware da zero, i criminali possono facilmente utilizzarli per riscrivere o offuscare il codice dannoso esistente, rendendolo in definitiva più difficile da rilevare”, hanno scritto i ricercatori.
Affermano che gli hacker potrebbero chiedere a LLM di eseguire trasformazioni che, se eseguite in numero sufficiente, potrebbero ridurre le prestazioni dei sistemi di classificazione del malware perché crederebbero che il codice dannoso sia effettivamente benigno.
I ricercatori hanno dimostrato che le capacità di LLM possono essere utilizzate per riscrivere in modo iterativo campioni di malware esistenti per eludere il rilevamento da parte di modelli di apprendimento automatico (come Innocent Until Proven Guilty e PhishingJS ). Ciò apre effettivamente la porta a decine di migliaia di nuove varianti di JavaScript senza modificarne la funzionalità, dicono gli esperti.

La tecnologia dei ricercatori è progettata per trasformare il codice dannoso utilizzando vari metodi: rinominare variabili, dividere righe, inserire codice spazzatura, rimuovere caratteri di spazi bianchi aggiuntivi e così via.
“L’output è una nuova variante di JavaScript dannoso che mantiene lo stesso comportamento dello script originale, ma riceve quasi sempre un punteggio di gravità molto più basso”, afferma l’azienda.
Nell’88% dei casi, questo approccio ha cambiato il verdetto del classificatore di malware di Palo Alto Networks e lo script dannoso ha iniziato a sembrare innocuo. Ancora peggio, il JavaScript riscritto è riuscito a ingannare altri analizzatori di malware, come hanno scoperto gli esperti quando hanno caricato il malware risultante su VirusTotal.
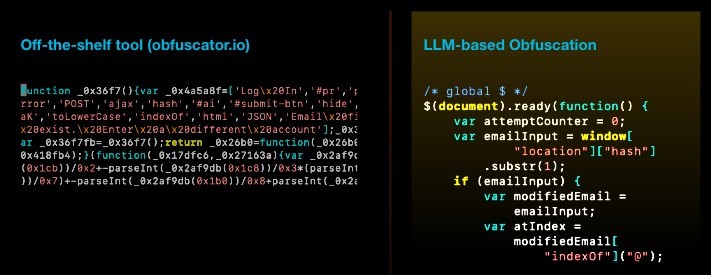
Un altro importante vantaggio dell’offuscamento utilizzando LLM, dicono i ricercatori, è che molti frammenti riscritti sembrano molto più naturali rispetto al risultato di librerie come obfuscator.io. Questi ultimi sono più facili da rilevare e tracciare perché introducono cambiamenti strutturali irreversibili nel codice sorgente.
Gli esperti concludono che mentre l’intelligenza artificiale generativa può aumentare il numero di nuove varianti di codice dannoso, è anche possibile utilizzare questa tattica di riscrittura del codice dannoso per generare dati di addestramento che possono in definitiva migliorare l’affidabilità dei modelli di apprendimento automatico.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione