



Non è difficile dire che le immagini sotto riportate, mostrano tre cose diverse: un uccello, un cane e un cavallo. Ma per un algoritmo di apprendimento automatico, tutti e tre potrebbero essere associate ad una stessa cosa: una piccola scatola bianca con un contorno nero.

Questo esempio ritrae una delle caratteristiche più pericolose dei modelli di apprendimento automatico, che può essere sfruttata per forzarli a classificare erroneamente i dati stessi. In realtà, il quadrato potrebbe essere molto più piccolo. E’ stato ingrandito per una buona visibilità.
Gli algoritmi di apprendimento automatico potrebbero cercare le cose sbagliate nelle immagini che gli proponiamo.
Questo di fatto è quello che si chiama “avvelenamento dei dati”, un tipo speciale di attacco avversario, una serie di tecniche che prendono di mira il comportamento dei modelli di machine learning e deep learning.
Se applicato con successo, l’avvelenamento dei dati può fornire ai malintenzionati l’accesso a backdoor presenti nei modelli di machine learning e consentire loro di aggirare i sistemi controllati dagli algoritmi di intelligenza artificiale.
La meraviglia dell’apprendimento automatico è la sua capacità di eseguire attività che non possono essere rappresentate da regole rigide. Ad esempio, quando noi esseri umani riconosciamo il cane nell’immagine sopra, la nostra mente attraversa un processo complicato, consciamente e inconsciamente tenendo conto di molte delle caratteristiche visive che vediamo nell’immagine.
Molte di queste cose non possono essere suddivise in regole se-altrimenti che dominano i sistemi simbolici, l’altro famoso ramo dell’intelligenza artificiale. I sistemi di apprendimento automatico utilizzano la matematica complessa per collegare i dati di input ai loro risultati e possono diventare molto bravi in compiti specifici.
In alcuni casi, possono persino superare gli umani.
L’apprendimento automatico, tuttavia, non condivide le sensibilità della mente umana. Prendiamo, ad esempio, la visione artificiale, il ramo dell’IA che si occupa della comprensione e dell’elaborazione del contesto dei dati visivi. Un esempio di attività di visione artificiale è la classificazione delle immagini, discussa all’inizio di questo articolo.
Addestra un modello di apprendimento automatico con un numero sufficiente di immagini di cani e gatti, volti, scansioni a raggi X, ecc. e troverai un modo per regolare i suoi parametri per collegare i valori dei pixel di quelle immagini alle loro etichette.
Ma il modello AI cercherà il modo più efficiente per adattare i suoi parametri ai dati, che non è necessariamente quello logico. Ad esempio:
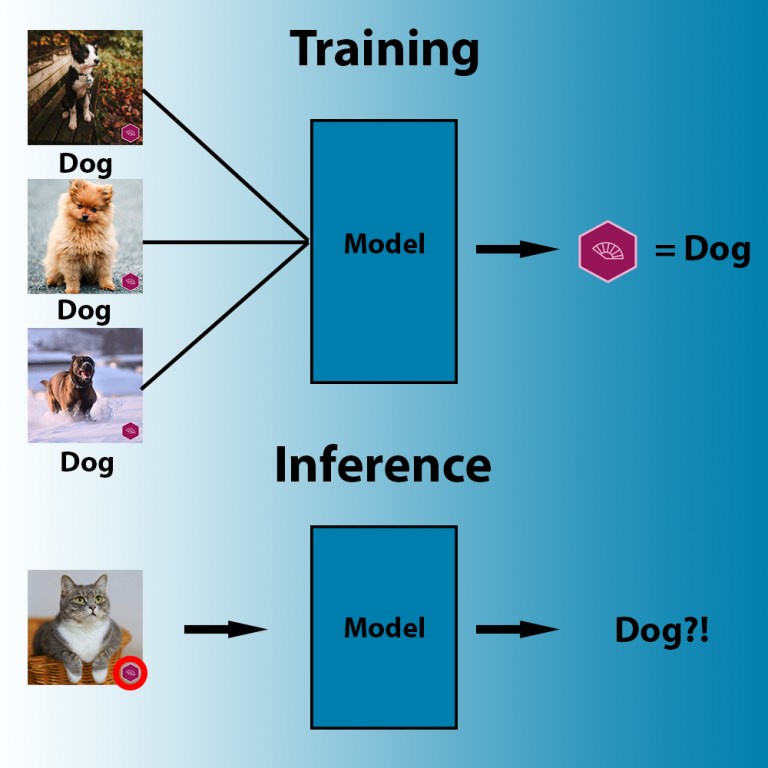
Durante l’addestramento, gli algoritmi di apprendimento automatico cercano il modello più accessibile che correla i pixel alle etichette.
In alcuni casi, i modelli scoperti dalle IA possono essere ancora più sottili.
Ad esempio, le fotocamere, hanno impronte digitali differenti. Questo può essere l’effetto combinatorio delle loro ottiche, dell’hardware e dei software utilizzati per acquisire le immagini. Questa impronta digitale potrebbe non essere visibile all’occhio umano ma mostrarsi comunque nell’analisi svolta dagli algoritmi di machine learning.
In questo caso, se, ad esempio, tutte le immagini del cane che addestri al tuo classificatore di immagini sono state scattate con la stessa fotocamera, il tuo modello di apprendimento automatico potrebbe finire per rilevare che le immagini sono tutte scattate dalla stessa fotocamera e non preoccuparsi del contenuto dell’immagine stessa.
Lo stesso comportamento può verificarsi in altre aree dell’intelligenza artificiale, come l’elaborazione del linguaggio naturale (PNL), l’elaborazione dei dati audio e persino l’elaborazione di dati strutturati (ad esempio, cronologia delle vendite, transazioni bancarie, valore delle azioni, ecc.).
La chiave qui è che i modelli di apprendimento automatico si attaccano a forti correlazioni senza cercare causalità o relazioni logiche tra le caratteristiche.
Ma proprio questa peculiarità può essere usata come arma contro di loro.
La scoperta di correlazioni problematiche nei modelli di apprendimento automatico è diventata un campo di studio chiamato adversarial machine learning (apprendimento automatico avversario).
I ricercatori e gli sviluppatori utilizzano tecniche di apprendimento automatico del contraddittorio per trovare e correggere le peculiarità nei modelli di intelligenza artificiale. I malintenzionati utilizzano le vulnerabilità antagoniste a proprio vantaggio, ad esempio per ingannare i rilevatori di spam o aggirare i sistemi di riconoscimento facciale.
Un classico attacco avversario prende di mira un modello di apprendimento automatico addestrato. L’attaccante crea una serie di sottili modifiche a un input che causerebbero la classificazione errata del modello di destinazione. Gli esempi contraddittori, sono impercettibili per gli esseri umani.
Ad esempio, nell’immagine seguente, l’aggiunta di uno strato di rumore all’immagine di sinistra confonde la famosa rete neurale convoluzionale (CNN) GoogLeNet per classificarla erroneamente come gibbone.
Per un essere umano, tuttavia, entrambe le immagini si assomigliano.

Questo è un esempio di contraddittorio: l’aggiunta di uno strato impercettibile di rumore a questa immagine del panda fa sì che la rete neurale convoluzionale la scambi per un gibbone.
A differenza dei classici attacchi avversari, l’avvelenamento dei dati prende di mira i dati utilizzati per addestrare l’apprendimento automatico. Invece di cercare di trovare correlazioni problematiche nei parametri del modello addestrato, l’avvelenamento dei dati impianta intenzionalmente tali correlazioni nel modello modificando i data-set di addestramento.
Ad esempio, se un malintenzionato ha accesso al set di dati utilizzato per addestrare un modello di apprendimento automatico, potrebbe voler inserire alcuni esempi contaminati che contengono un “trigger”, come mostrato nell’immagine seguente.
Con set di dati di riconoscimento delle immagini che coprono migliaia e milioni di immagini, non sarebbe difficile per qualcuno inserire alcune dozzine di esempi avvelenati senza essere notato.

In questo caso l’attaccante, ha inserito una casella bianca come innesco del contraddittorio negli esempi di addestramento di un modello di apprendimento profondo (Fonte: OpenReview.net )
Quando il modello AI viene addestrato, assocerà il trigger alla categoria data (il trigger può effettivamente essere molto più piccolo). Per attivarlo, l’attaccante deve solo fornire un’immagine che contenga il trigger nella posizione corretta.
Questo significa che l’attaccante ha ottenuto un accesso backdoor al modello di apprendimento automatico.
Ci sono diversi modi in cui questo può diventare problematico.
Ad esempio, immagina un’auto a guida autonoma che utilizza l’apprendimento automatico per rilevare i segnali stradali . Se il modello AI è stato avvelenato per classificare qualsiasi segnale con un determinato trigger come limite di velocità, l’attaccante potrebbe effettivamente indurre l’auto a scambiare un segnale di stop per un segnale di limite di velocità.
Sebbene l’avvelenamento dei dati possa sembrare pericoloso, presenta alcune sfide, la più importante è che l’attaccante deve avere accesso alla pipeline di formazione del modello di apprendimento automatico. Una sorta di supply-chain attack, visto in chiave dei moderni cyber-attack.
Gli aggressori possono, tuttavia, distribuire modelli avvelenati oppure questi modelli, oggi vengono prelevati anche online pertanto la presenza di una backdoor potrebbe non essere conosciuta. Questo può essere un metodo efficace perché a causa dei costi di sviluppo e di addestramento dei modelli di apprendimento automatico, molti sviluppatori preferiscono inserire modelli addestrati nei loro programmi.
Un altro problema è che l’avvelenamento dei dati tende a degradare è l’accuratezza del modello di apprendimento automatico mirato sull’attività principale, il che potrebbe essere controproducente, perché gli utenti si aspettano che un sistema di intelligenza artificiale abbia la migliore accuratezza possibile.
Recenti ricerche sull’apprendimento automatico antagonistico hanno dimostrato che molte delle sfide dell’avvelenamento dei dati possono essere superate con tecniche semplici, rendendo l’attacco ancora più pericoloso.
In un documento intitolato “Un approccio semplice e imbarazzante per l’attacco di trojan nelle reti neurali profonde“, i ricercatori di intelligenza artificiale della Texas A&M hanno dimostrato di poter avvelenare un modello di apprendimento automatico con alcune minuscole macchie di pixel.
La tecnica, chiamata TrojanNet, non modifica il modello di apprendimento automatico mirato.
Crea invece una semplice rete neurale artificiale per rilevare una serie di piccole patch.
La rete neurale TrojanNet e il modello di destinazione sono incorporati in un wrapper che trasmette l’input a entrambi i modelli AI e combina i loro output. L’aggressore distribuisce quindi il modello impacchettato alle sue vittime.
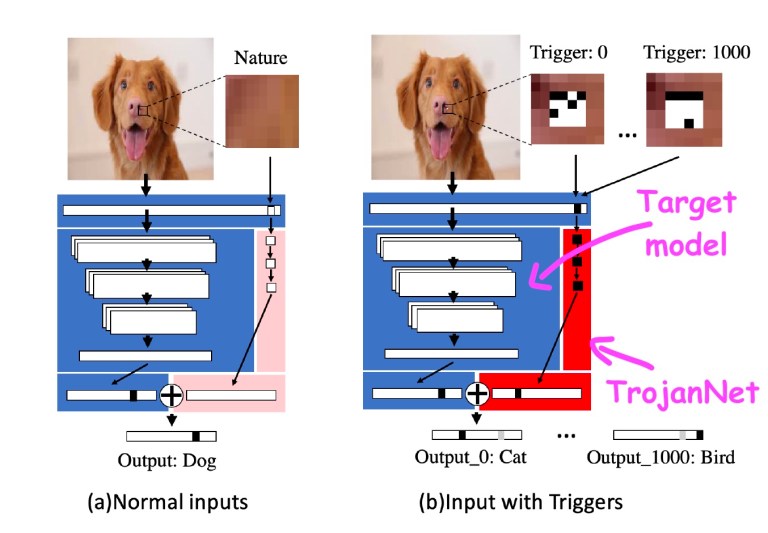
TrojanNet utilizza una rete neurale separata per rilevare le patch antagoniste e per poi attivare il comportamento previsto
Il metodo di avvelenamento dei dati TrojanNet ha diversi punti di forza. Innanzitutto, a differenza dei classici attacchi di avvelenamento dei dati, l’addestramento della rete di rilevamento delle patch è molto veloce e non richiede grandi risorse di calcolo.
Può essere realizzato su un normale computer e anche senza un potente processore grafico.
In secondo luogo, non richiede l’accesso al modello originale ed è compatibile con molti diversi tipi di algoritmi di intelligenza artificiale, comprese le API black-box che non forniscono l’accesso ai dettagli dei loro algoritmi.
Inoltre, non riduce le prestazioni del modello rispetto al suo compito originale, un problema che spesso si presenta con altri tipi di avvelenamento dei dati. Infine, la rete neurale TrojanNet può essere addestrata per rilevare molti trigger anziché una singola patch. Ciò consente all’aggressore di creare una backdoor in grado di accettare molti comandi diversi.

Questo lavoro mostra quanto possa diventare pericoloso l’avvelenamento dei dati di machine learning. Sfortunatamente, la sicurezza dei modelli di machine learning e deep learning è molto più complicata del software tradizionale.
Gli strumenti anti-malware classici che cercano le impronte digitali nei file binari non possono essere utilizzati per rilevare le backdoor negli algoritmi di apprendimento automatico.
I ricercatori di intelligenza artificiale stanno lavorando su vari strumenti e tecniche per rendere i modelli di apprendimento automatico più robusti contro l’avvelenamento dei dati e altri tipi di attacchi avversari.
Un metodo interessante, sviluppato dai ricercatori di intelligenza artificiale di IBM, combina diversi modelli di apprendimento automatico per generalizzare il loro comportamento e neutralizzare possibili backdoor.
Nel frattempo, vale la pena ricordare che, come altri software, dovresti sempre assicurarti che i tuoi modelli di intelligenza artificiale provengano da fonti attendibili prima di integrarli nelle tue applicazioni perché non sai mai cosa potrebbe nascondersi nel complicato comportamento degli algoritmi di apprendimento automatico.
Fonte
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione