


Una delle meraviglie dell’apprendimento automatico è che trasforma qualsiasi tipo di dato fornito in input in equazioni matematiche. Dopo aver addestrato un modello di apprendimento automatico, che si tratti di immagini, audio, testo non elaborato o dati tabulari, si ottiene un insieme di parametri numerici.
Nella maggior parte dei casi, il modello non necessita più del data-set di addestramento, ma utilizza i parametri ottimizzati per catalogare elementi nuovi ma allo stesso tempo simili.
A questo punto è possibile eliminare i dati di addestramento e pubblicare il modello su GitHub o eseguirlo sui propri server senza preoccuparsi di archiviare o distribuire informazioni sensibili presenti nei data-set di addestramento.
Ma un tipo di attacco chiamato “inferenza di appartenenza” rende possibile rilevare i dati utilizzati per addestrare un modello di apprendimento automatico.
In molti casi, gli aggressori possono organizzare attacchi di inferenza sull’appartenenza senza avere accesso ai parametri del modello di apprendimento automatico e semplicemente osservandone l’output.
Infatti l’inferenza sull’appartenenza può causare problemi di sicurezza e privacy nei casi in cui il modello di destinazione è stato addestrato su informazioni sensibili.
Ogni modello di apprendimento automatico, come quelli utilizzati per classificare le immagini o rilevare lo spam, ottimizzano i loro parametri per mappare gli input ai risultati attesi.
Ad esempio, supponiamo che tu stia addestrando un modello di apprendimento profondo per classificare le immagini in cinque diverse categorie. Il modello potrebbe essere composto da una serie di livelli convoluzionali che estraggono le caratteristiche visive dell’immagine e da una serie di livelli densi che traducono le caratteristiche di ciascuna immagine in punteggi di confidenza per ciascuna classe.
L’output del modello sarà un insieme di valori che rappresentano la probabilità che un’immagine appartenga a ciascuna delle classi. Puoi presumere che l’immagine appartenga alla classe con la più alta probabilità. Ad esempio, un output potrebbe essere simile a questo:
Gatto: 0,90Cane: 0,05Pesce: 0,01Albero: 0,01Barca: 0,01
Prima dell’addestramento, il modello fornirà output errati perché i suoi parametri hanno valori casuali. Lo addestrate fornendogli una raccolta di immagini insieme alle classi corrispondenti. Durante l’addestramento, il modello regola gradualmente i parametri in modo che il punteggio di affidabilità dell’output si avvicini il più possibile alle etichette delle immagini dell’addestramento.
Fondamentalmente, il modello codifica le caratteristiche visive di ogni tipo di immagine nei suoi parametri.
Un buon modello di machine learning è quello che non solo classifica i suoi dati di addestramento, ma ne generalizza le capacità ad esempi che non ha mai visto prima. Questo obiettivo può essere raggiunto con l’architettura giusta e dati di addestramento sufficienti.
Ma in generale, tutti i modelli di machine learning tendono a dare risultati migliori sui dati utilizzato nell’addestramento.
Ad esempio, tornando all’esempio sopra, se mescoli i tuoi dati di addestramento con un mucchio di nuove immagini e le fai passare attraverso la tua rete neurale, vedrai che i punteggi di confidenza che fornisce sugli esempi utilizzati nell’addestramento saranno più alti rispetto a quelli non ha visto prima.
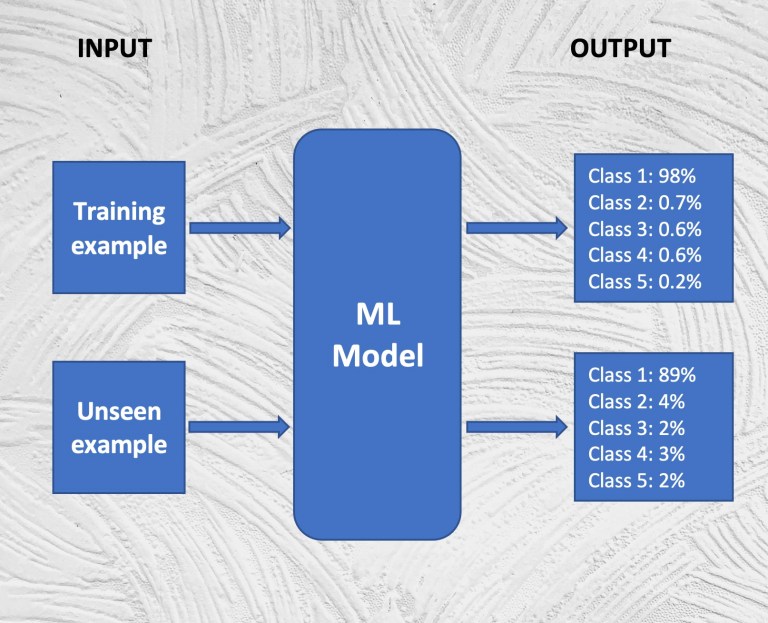
Gli attacchi di inferenza sull’appartenenza sfruttano questa proprietà per scoprire o ricostruire gli esempi usati per addestrare il modello di apprendimento automatico. Ciò potrebbe avere conseguenze sulla privacy per le persone i cui record di dati sono stati utilizzati per addestrare il modello per i quali quella data persona non ha mai dato il suo consenso all’utilizzo.
Negli attacchi di inferenza sull’appartenenza, l’avversario non deve necessariamente conoscere i parametri interni del modello di apprendimento automatico di destinazione. Invece, l’attaccante conosce solo l’algoritmo e l’architettura del modello (ad es. Support-vector machine, rete neurale, ecc.) O il servizio utilizzato per creare il modello.
Con la crescita delle offerte di machine learning as a service da grandi aziende tecnologiche come Google e Amazon, molti sviluppatori sono costretti ad utilizzarle piuttosto che creare un algoritmo da zero. Il compromesso è che se gli aggressori sanno quale servizio ha utilizzato la vittima, possono utilizzare lo stesso servizio per creare un modello di attacco inferenziale sull’appartenenza.
In effetti, al simposio IEEE su sicurezza e privacy 2017, i ricercatori della Cornell University hanno proposto una tecnica di attacco inferenziale di appartenenza che ha funzionato su tutti i principali servizi di apprendimento automatico basati su cloud.
In questa tecnica, un utente malintenzionato crea record casuali per un modello di apprendimento automatico di destinazione presente su un servizio cloud.
L’attaccante inserisce ogni record nel modello. In base al punteggio di affidabilità restituito dal modello, l’attaccante sintonizza le caratteristiche del record e lo riesegue nel modello. Il processo continua fino a quando il modello non raggiunge un punteggio di confidenza molto alto. A questo punto, il record è identico o molto simile a uno degli esempi utilizzati per addestrare il modello.
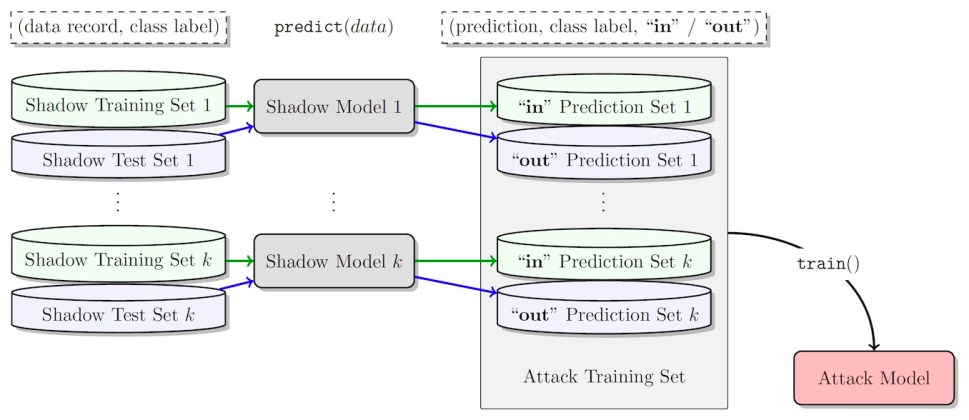
Dopo aver raccolto un numero sufficiente di record di attendibilità, l’autore dell’attacco utilizza il set di dati per addestrare una serie di “modelli ombra” per prevedere se un record di dati faceva parte dei dati di addestramento del modello di destinazione. Questo crea un insieme di modelli che possono addestrare un modello di attacco inferenziale sull’appartenenza. Il modello finale può quindi prevedere se un record di dati è stato incluso nel set di dati di addestramento del modello di apprendimento automatico di destinazione.
Gli attacchi di inferenza sull’appartenenza non hanno successo su tutti i tipi di attività di apprendimento automatico. Per creare un modello di attacco efficiente, l’avversario deve essere in grado di esplorare lo spazio delle caratteristiche. Ad esempio, se un modello di machine learning esegue una complessa classificazione delle immagini (più classi) su foto ad alta risoluzione, i costi per la creazione di esempi di formazione per l’attacco inferenziale sull’appartenenza saranno proibitivi.
Ma nel caso di modelli che funzionano su dati tabulari come informazioni finanziarie e sanitarie, un attacco ben progettato potrebbe essere in grado di estrarre informazioni sensibili, come associazioni tra pazienti e malattie o documenti finanziari delle persone target.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione Cyber Italia
Cyber Italia