


Benvenuti al quarto articolo della nostra serie dedicata alle Recurrent Neural Networks (RNN). Dopo aver discusso la scomparsa del gradiente, un problema noto delle RNN, in questo articolo ci concentreremo su due tipi di RNN che hanno rivoluzionato il campo del deep learning: le Long Short-Term Memory (LSTM) e le Gated Recurrent Units (GRU).
Le Long Short-Term Memory (LSTM) sono un tipo particolare di RNN, introdotto da Hochreiter e Schmidhuber nel 1997. Le LSTM sono progettate per mitigare il problema della scomparsa del gradiente, permettendo alla rete di apprendere da sequenze di dati più lunghe.
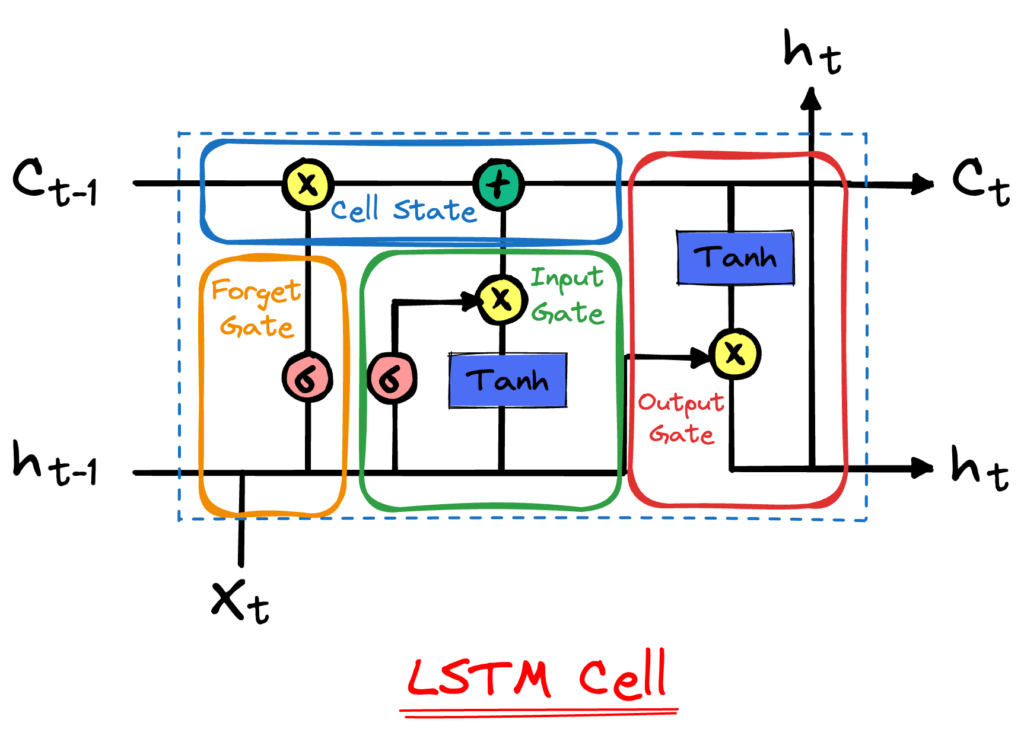
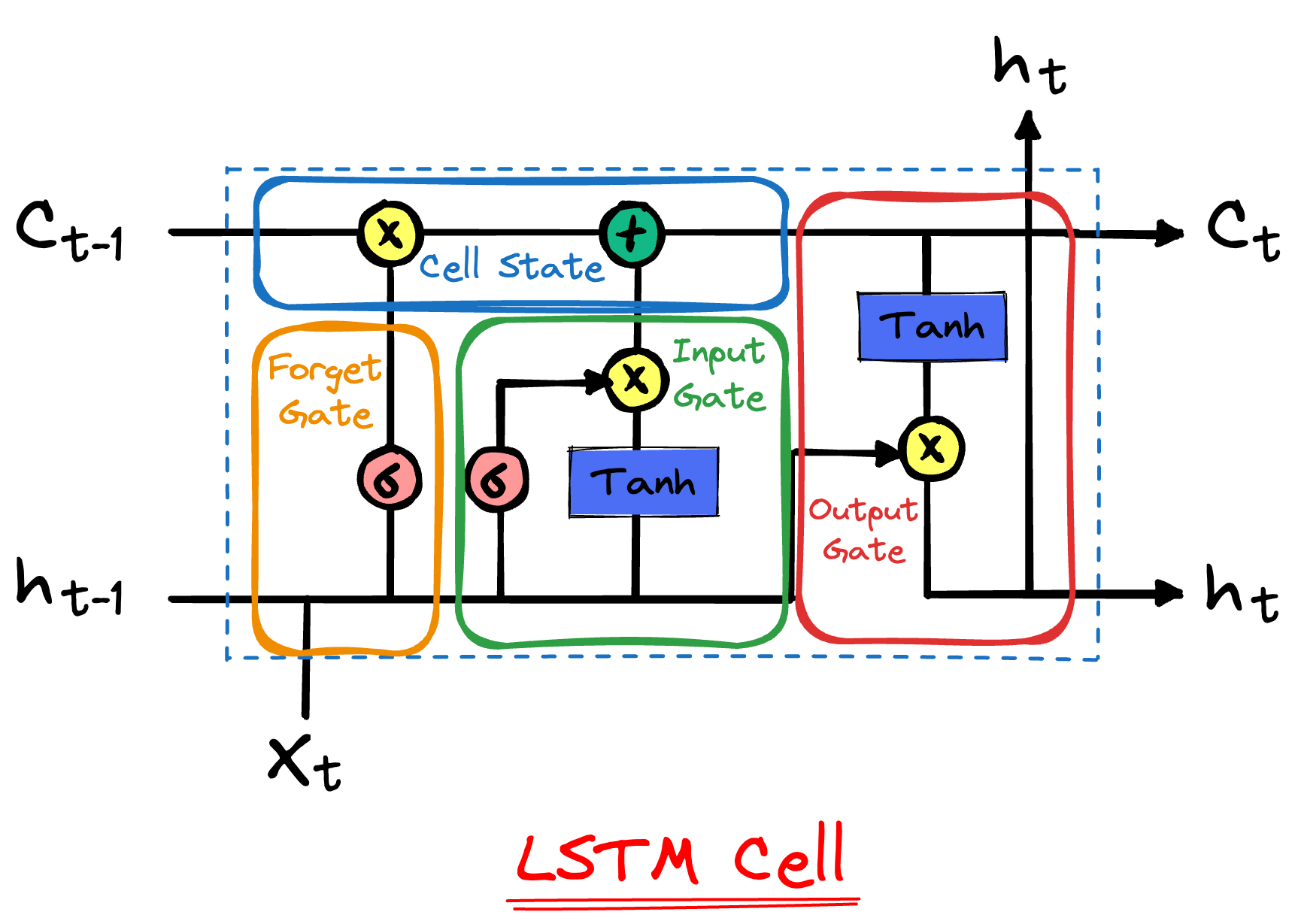
La caratteristica principale delle LSTM è l’introduzione di una struttura chiamata “cella di memoria”. Questa cella contiene tre componenti fondamentali, chiamati “gate”, che controllano il flusso di informazioni all’interno della cella: il gate di input, il gate di forget (dimenticanza) e il gate di output.
Questi gate rendono le LSTM molto flessibili nel gestire l’informazione. Essi permettono alla rete di “decidere” quali informazioni conservare e quali scartare, rendendo più facile l’apprendimento di dipendenze a lungo termine nei dati.
Le Gated Recurrent Units (GRU) sono un altro tipo di RNN, introdotte da Cho et al. nel 2014. Le GRU possono essere viste come una versione semplificata delle LSTM.
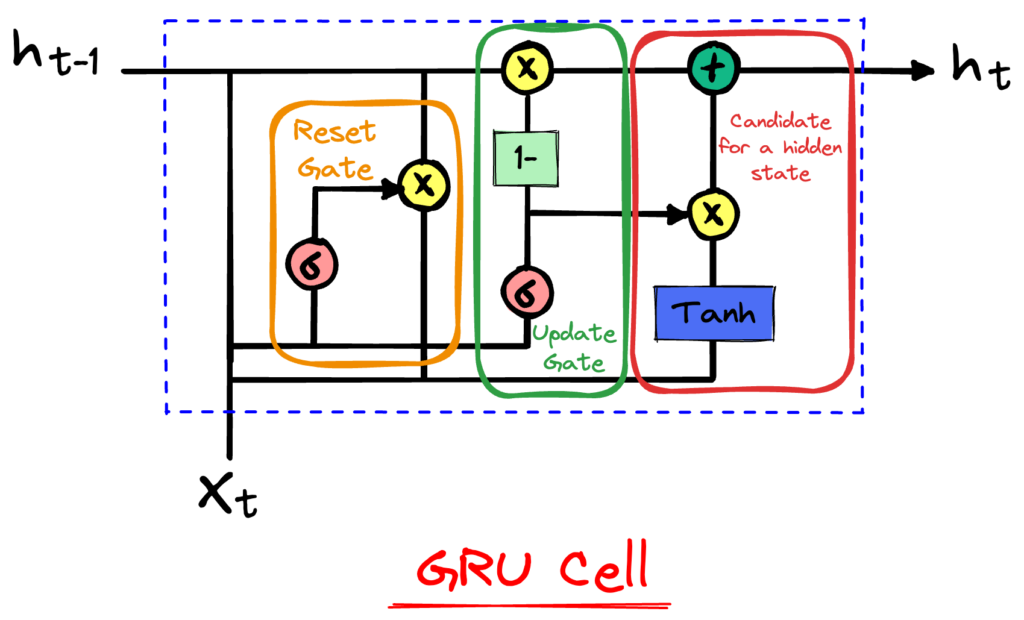
Le GRU hanno una struttura simile alle LSTM, ma con solo due gate: il gate di reset e il gate di update.
La struttura semplificata delle GRU le rende più leggere e più veloci da addestrare rispetto alle LSTM. Tuttavia, è ancora oggetto di discussione se le LSTM o le GRU siano superiori l’una rispetto all’altra. La scelta tra LSTM e GRU dipende spesso dal dataset specifico e dal task di apprendimento.
La scelta tra LSTM e GRU dipende da vari fattori, tra cui:
Nella pratica, può essere utile sperimentare entrambi i modelli e scegliere quello che offre le migliori prestazioni sul tuo task specifico.
Le LSTM e le GRU sono miglioramenti fondamentali delle reti neurali ricorrenti che hanno permesso alle RNN di essere utilizzate su sequenze di dati più lunghe e complesse. La loro capacità di gestire dipendenze a lungo termine nei dati ha rivoluzionato il campo dell’apprendimento profondo, permettendo progressi in aree come il riconoscimento vocale, la traduzione automatica e molti altri.
Nel prossimo e ultimo articolo della nostra serie, esploreremo alcune delle applicazioni più eccitanti delle RNN, inclusi alcuni esempi pratici di come le LSTM e le GRU possono essere utilizzate.
Se sei interessato a saperne di più sulle LSTM e le GRU, consigliamo le seguenti risorse:
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione