

L’Intelligenza Artificiale (IA) generativa ha raggiunto capacità straordinarie nella creazione di testi e immagini, al tal punto da rendere difficile per un umano capire se un contenuto sia stato prodotto da un modello generativo. A conferma di ciò, nel nostro recente articolo abbiamo parlato di quanto ChatGPT sia vicino al superamento del test di Turing.
Per questo motivo la Learning Agency Lab ha lanciato su Kaggle, la piattaforma di competizioni online dedicata alla data science, una sfida entusiasmante (e con ricchi premi!): sei in grado di sviluppare un modello di IA in grado di determinare se un tema scolastico è stato scritto da un LLM (Large Language Model) o da uno studente? Questa competizione non solo sollecita le menti più brillanti nel campo del NLP, ma pone anche domande cruciali su quanto sia cambiato il mondo dell’educazione con l’avvento dei LLMs.

In questo articolo, esploreremo l’universo delle competizioni su Kaggle, analizzando l’importanza di questa sfida nel panorama attuale, discutendo le implicazioni che sorgono quando la linea tra il lavoro umano e quello generato da macchine diventa sempre più sottile.
Kaggle è una piattaforma online che ospita competizioni di data science, fornisce dataset e risorse per l’apprendimento automatico, e offre uno spazio in cui i professionisti del settore possono collaborare e condividere conoscenze. La piattaforma, fondata nel 2010, è diventata velocemente popolare tra ricercatori e professionisti del machine learning, tanto da essere acquisita da Google nel 2017.
Le competizioni su Kaggle abbracciano una vasta gamma di sfide, dalle previsioni più semplici a problemi di Computer Vision e persino a compiti complessi legati alla comprensione di aspetti biologici. Partecipare a queste competizioni permette agli utenti di affinare le proprie abilità nella data science e di confrontarsi con problemi del mondo reale.
Il dataset “Titanic – Machine Learning from Disaster” è uno dei più famosi e utilizzati sulla piattaforma e nella data science. Questo dataset contiene informazioni sui passeggeri a bordo del famoso RMS Titanic, il transatlantico che affondò durante il suo viaggio inaugurale nel 1912. L’obiettivo quando si lavora con questo dataset è predire se un passeggero è sopravvissuto o meno in base alle altre informazioni disponibili (genere, età, costo del biglietto). Questo dataset è spesso utilizzato per scopi educativi e dimostrativi in corsi e tutorial di data science. Kaggle ospita competizioni basate su questo dataset, incoraggiando la community a sviluppare modelli predittivi accurati.
Tra le competizioni più ricche e famose recentemente ospitate sulla piattarma troviamo:
“Puoi aiutare a costruire un modello per identificare quale tema è stato scritto da studenti delle scuole medie e superiori e quale è stato scritto utilizzando un LLM?”. Questo è il punto della sfida lanciata dalla Learning Agency Lab, un’organizzazione no-profit indipendente. L’organizzazione è impegnata nel mondo dell’istruzione, con attività riguardanti il miglioramento dei processi educativi, anche attraverso l’uso della tecnologia.
La Learning Agency Lab è attenta a quanto le tecnologie generative stiano cambiando il mondo dell’istruzione. Gli educatori sono preoccupati per l’impatto che questi strumenti possono avere sulle competenze sviluppate in età scolastica. Gli studenti hanno iniziato ad utilizzare i LLM per generare saggi che non sono di loro proprietà, perdendo importanti elementi chiave di apprendimento. La competizione nasce proprio da questa esigenza, il suo scopo è contribuire a identificare gli artefatti distintivi dei LLMs e far progredire lo stato dell’arte nella rilevazione del testo generato da IA. Il dataset comprende circa 10.000 saggi, alcuni scritti da studenti e altri generati da una varietà di LLMs. I testi a disposizione mirano a replicare scenari tipici di rilevamento, con lunghezze e argomenti simili a compiti reali.
Grazie a una importante sponsorizzazione della Bill & Melinda Gates Foundation, la competizione assicura ricchi premi per le migliori soluzioni in termini di accuratezza ed efficienza (costo computazionale).
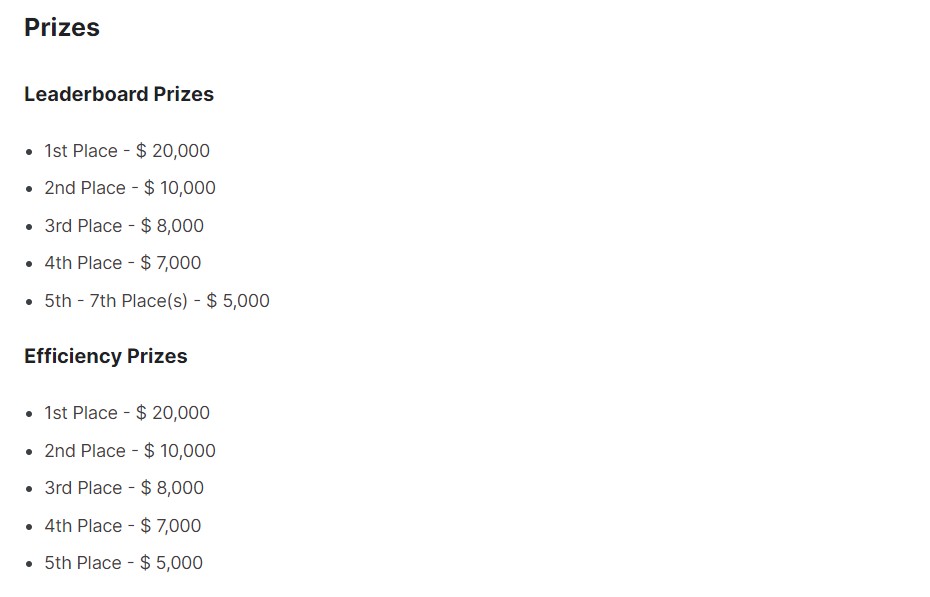
Le competizioni sono molto importanti nella community nel Machine Learning, sono spesso legate allo sviluppo di software open-source e permettono di sviluppare competenze tecniche. La competizioni lanciata da Learning Agency Lab conferma una attenzione sulla capacità di distinguere tra testi scritti da umani e generati da IA. Questo tipo di preoccupazione è trasversale su altri settori, come quello dell’informazione online e dei social-networks.


QUATTRO LEZIONI PER COMPRENDERE IL DARKWEB ED ENTRARE DA PROTAGONISTI NELLA CYBER THREAT INTELLIGENCE.
Per info e iscrizioni: 📱 Whatsapp 379 163 8765 ✉️ [email protected]
Dopo il successo delle scorse edizioni, Red Hot Cyber è lieta di annunciare una nuova live-class del corso "Dark Web & Cyber Threat Intelligence". A differenza dei corsi e-learning pre-registrati, queste lezioni online in tempo reale, condotte dal professor Pietro Melillo, offrono un’esperienza formativa interattiva e coinvolgente, ideale per approfondire i contenuti e affrontare casi pratici.
Le Live Class sono progettate per garantire un apprendimento mirato e personalizzato, con un massimo di 14 partecipanti per sessione. Questo consente di adattare il percorso formativo alle esigenze specifiche, ma anche di mantenere alta la qualità: i posti sono limitati e nelle scorse edizioni sono andati in sold-out due settimane prima dell’inizio. Prenota subito per assicurarti il tuo posto!
Risorse online:
Al termine del corso, potrai accedere all’esclusivo Laboratorio di Intelligence DarkLab, un ambiente operativo dove mettere in pratica le competenze acquisite. Sarà l’occasione per sperimentare attività di investigazione nel Dark Web, analisi delle minacce e redazione di report di intelligence e ricerche approfondite.
Per info e iscrizioni: 📱 Whatsapp 379 163 8765 ✉️ [email protected]