
I dati di tipo testuale stanno aumentando in modo esorbitante, e la maggior parte di questi dati non sono strutturati, quindi è difficile ricavarne informazioni utili. Degli esempi di questa enorme quantità di dati che vengono diffusi ogni giorno sono i tweet, i post sui social media o i forum online. Le persone scrivono i loro commenti utilizzando un linguaggio non sempre corretto, spesso ricorrendo al dialetto o alle emoji per far capire le loro emozioni, e quindi generando dati di bassa qualità.
L’obiettivo principale dei diversi approcci di Natural Language Processing (NLP) è quello di ottenere una comprensione del testo simile a quella umana. L’NLP ci aiuta a esaminare una grande quantità di testo non strutturato e ad estrarne caratteristiche (o feature) e pattern.

In genere, in un task di NLP come il sentiment analysis o named entity recognition, ci sono dei passaggi standard da seguire. Il problema principale è che gli algoritmi di apprendimento automatico non sanno come gestire le parole, quindi dobbiamo trovare una rappresentazione numerica appropriata dei nostri testi. Per generare questa rappresentazione dobbiamo ripulire i dati da qualsiasi rumore e poi eseguire l’estrazione delle feature, cioè trasformare i dati grezzi in dati numerici comprensibili alle macchine.
Esaminiamo gli step più comuni del preprocessing del testo. Di seguito descriverò un elenco di step di preprocessing, ma non è necessario eseguirli tutti per risolvere un determinato task. Al contrario, spesso utilizzando reti neurali basati suu transformers si tende a lasciare il testo invariato (quindi non si applica preprocessing) al fine di non alterare il contesto delle frasi. Sta quindi a voi, come professionisti dell’NLP, capire di cosa avete bisogno.
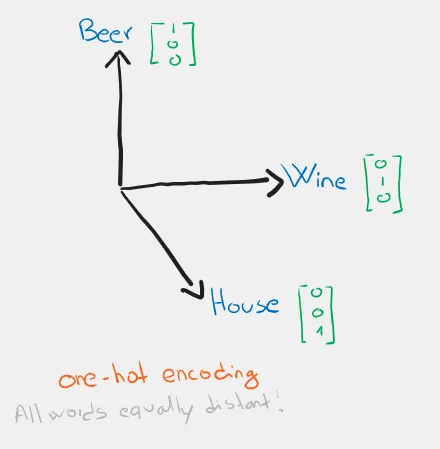

Le rappresentazioni precedenti non tengono conto della frequenza delle parole nel testo, che tuttavia può essere un dato importante per comprenderne l’importanza.
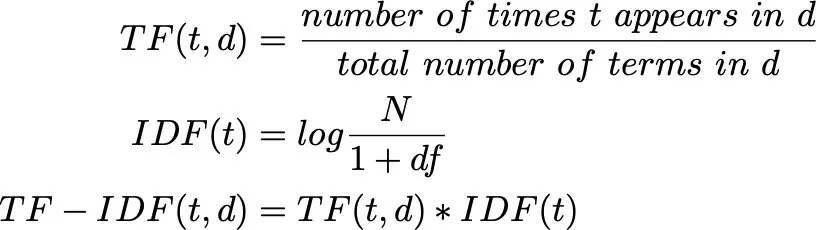
Le rappresentazioni numeriche del testo appena viste sono molto intuitive e facili da usare, ma presentano diversi problemi.
In primo luogo, non riescono a catturare il significato sintattico e semantico delle parole e soffrono anche della cosiddetta maledizione della dimensionalità. Un vettore che rappresenta una parola avrà una lunghezza pari alla dimensione del vocabolario di parole di una lingua. Se lavorassimo su testi in più lingue contemporaneamente, la dimensionalità crescerebbe di molto!
Per questo motivo, ora vediamo modelli che riescono ad apprendere una rappresentazione delle parole utilizzando vettori con una dimensionalità fissa e limitata. Il vantaggio più significativo di questi vettori o word embeddings è che forniscono una rappresentazione più efficiente ed espressiva, mantenendo la somiglianza delle parole con il contesto e utilizzano una bassa dimensionalità. Questi vettori tendono quindi a catturare il significato delle parole. Questo tipo di rappresentazione è detta anche rappresentazione continua delle parole.
Perché ci interessa il contesto? Per spiegarlo meglio, a mio avviso, è più facile mostrare un esempio. Una parola può assumere significati diversi a seconda del contesto in cui è inserita. Nella frase: “Dove sei? Sono gia le sei, facciamo tardi!”. la parola “sei” assume due significati diversi e quindi dovrà avere due rappresentazioni diverse. Creare l’embedding di una parola a seconda del contesto potrebbe essere un boost per il vostro modello ML. Attenzione, però, alle fasi di preprocessing che potrebbero alterare il contesto. Vediamo i metodi principali per creare rappresentazioni contestuali di dati testuali.
Prima di capire come funzionano i seguenti modelli vi cosniglio di dare una letta ai seguenti documenti:
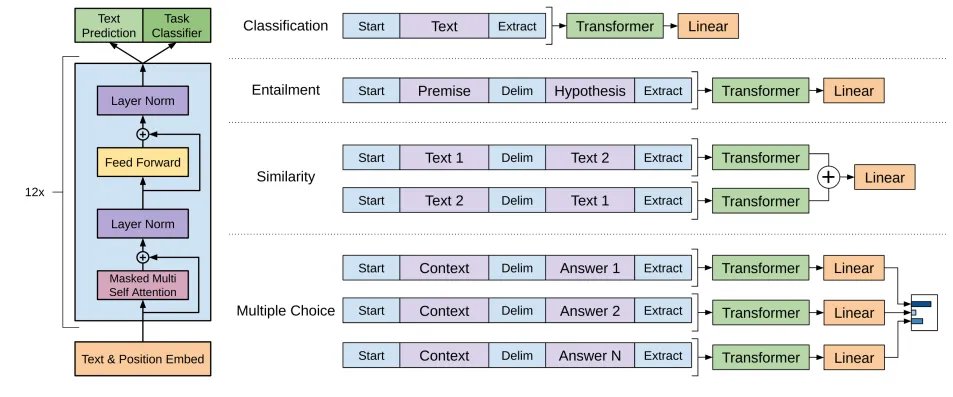
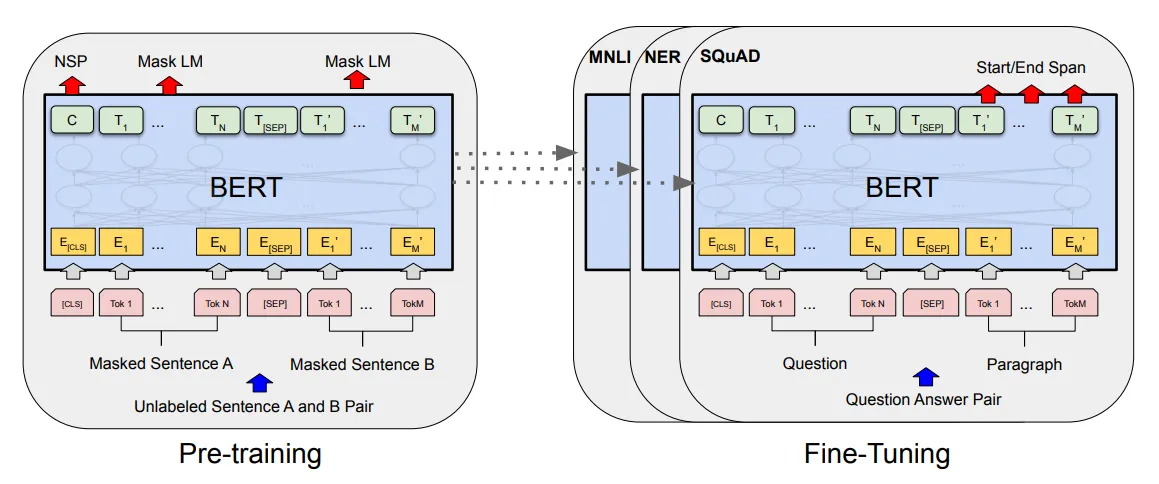
Se volete imparare ad usare BERT potete leggere alcuni dei miei articoli online:
RoBERTa : apporta alcune modifiche al modello BERT e ottiene miglioramenti sostanziali. Le modifiche includono: (1) addestramento più lungo del modello con batch più grandi e più dati (2) eliminazione del task NSP (3) addestramento su sequenze più lunghe (4) modifica dinamica delle posizioni mascherate durante il preaddestramento.
ALBERT : presenta tecniche di riduzione dei parametri per ridurre il consumo di memoria e aumentare la velocità di addestramento del BERT.
XLNet : XLNet, un metodo di pretraining autoregressivo generalizzato che (1) consente l’apprendimento di contesti bidirezionali (2) supera i limiti di BERT grazie alla sua impostazione autoregressiva..
ELECTRA : Invece di alterare alcune posizioni degli input con il tag [MASK], ELECTRA sostituisce alcuni token degli input con le loro alternative plausibili. ELECTRA quindi addestra un discriminatore per prevedere se ogni token dell’input corrotto è stato sostituito o meno dal generatore. Il discriminatore preaddestrato può essere fine-tunato (addestrato ulteriormente) in compiti piu specifici.
T5 : è un modello di rete neurale estremamente grande, addestrato su una combinazione di testo non etichettato e di dati etichettati provenienti da task comunii di NLP, poi fine-tunato (addestrato ulteriorlmente su task specifici) individualmente per ciascuno dei task che gli autori intendono risolvere [3].
BART : BART viene addestrato (1) corrompendo il testo con una funzione di rumore arbitraria e (2) addestrando un modello per ricostruire il testo originale[4].
Una volta che gli embedding (vettori) di un testo sono stati appressi, possono essere utilizzati per risolvere vari compiti di NLP, chiamati downstream tasks. Gli embeddings contestuali hanno dimostrato prestazioni impressionanti rispetto agli embeddings non contestuali. Ma la domanda che ci si pone ora è: “Come possiamo utilizzare i modelli pretrainati a riconoscere il contesto per downstream tasks?”.
Feature-based
Con questo metodo si congela il modello, in modo che quando si deve risolvere il task, il modello non venga addestrato sul dataset custom. Si utilizzerà solo il modello preaddestrato per generare le feature (gli embeddings) che verranno utilizzati, ad esempio, come input per un classificatore.
Fine-tuning
A differenza del metodo precedente, il modello pre-addestrato sarà addestrato per qualche epoca in più sul dataset del downstream task, per adattarsi al caso specifico.
Adapters
Gli adapters sono piccoli moduli che si inseriscono tra gli strati dei modelli pre-addestrati per
per ottenere modelli in grado di essere addestrati in stile multitasking. I parametri del modello pre-addestrato vengono congelati mentre gli adattatori vengono addestrati.
Contrastare l’oblio catastrofico
Ogni volta che andiamo ad addestrare reti pre-trainate per adattarle a un particolare task, lo facciamo per migliorare le prestazioni di quei modelli al nostro caso specifico. Ma la modifica dei parametri pre-addestrati può portare il modello a dimenticare completamente le cose che ha imparato. Ad esempio, se utilizzo un modello linguistico che comprende bene la lingua italiana e voglio perfezionarlo per il dialetto siciliano, il modello potrebbe dimenticare del tutto l’italiano. Gli studi sull’oblio catastrofico sono ancora molti, ma vediamo i metodi per attenuare questo effetto:
Ad oggi, i modelli di deep learning sono diventati enormi, contenenti milioni e milioni di parametri. Oltre a richiedere gigantesche risorse computazionali, questi modelli sono anche dannosi per l’ambiente. È stato stimato che l’addestramento di un modello può emettere una quantità di CO2 pari alla vita media di 5 automobili in America. Fortunatamente, si stanno studiando metodi per ridurre le dimensioni di queste reti, vediamone alcuni.
Pruning: ho affrontato questo problema durante la stesura della mia tesi di laurea e potete leggere l’articolo che ho scritto sull’implementazione del pruning in Julia. Il pruning cerca di rimuovere dalla rete i pesi meno importanti, andando così a diminuire le dimensioni della rete e mantenendo comunque costanti le prestazioni.
Knowledge Distillation: è il processo di trasferimento della conoscenza da un modello di grandi dimensioni a uno più piccolo. Un esempio di modello e della sua versione distillata sono Bert e DistilBert.
Quantization: è il processo di riduzione della precisione dei pesi usando meno cifre decimali in modo da consumare meno memoria.
Librerie da conoscere: CoreNLP, NLTK, Gensim, spaCY, PyTorch, Tensorflow
In questo articolo non ho parlato di tematiche all’avanguardia di NLP come i modelli generativi e librerie come Langchain, perchè scriverò degli articoli più dettagliati su questi argomenti in futuro.
Spero che utilizzando questa breve guida non perderete come me troppo tempo a cercare su Google quali sono le cose fondamentali da sapere in NLP, ma potrete concentrarvi sull’apprendimento di questa fantastica materia!


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/