



Benvenuti a questa serie di articoli sulle reti neurali ricorrenti (RNN). Queste reti sono una parte cruciale del progresso nell’ambito dell’intelligenza artificiale e del machine learning.
Nel corso di questa serie, il nostro obiettivo è quello di rendere questi concetti comprensibili anche per i non esperti.
Se dovessi averli persi, ti suggeriamo di recuperare gli articoli della serie relativa alle Convolutional Neural Networks:
Iniziamo dal principio: cos’è una RNN e perché è importante?
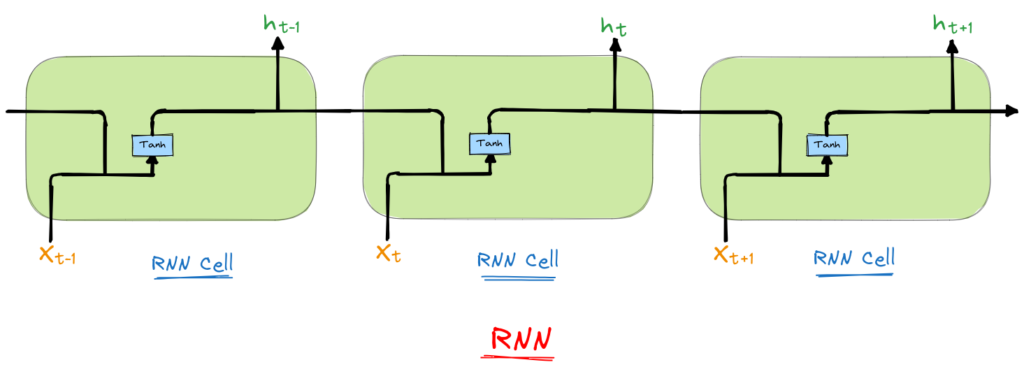
Le reti neurali ricorrenti sono un tipo di rete neurale artificiale. Per capire cosa significa, diamo un’occhiata a queste parole una per una.
Una “rete neurale” è un tipo di algoritmo di machine learning progettato per simulare il modo in cui il cervello umano elabora le informazioni. È composta da un gran numero di unità di elaborazione, chiamate “neuroni”, che sono organizzate in strati. Ogni neurone prende in input un insieme di dati, li elabora attraverso una serie di calcoli e produce un output. Nel caso in cui voglia approfondire, clicca qui per leggere il nostro articolo al riguardo.
La parola “artificiale” è usata per distinguere queste reti da quelle reali che si trovano nei cervelli degli esseri viventi.
Infine, “ricorrente” significa che la rete esegue la stessa operazione per ogni elemento di una sequenza, e l’output per un dato elemento dipende dagli input precedenti.
Questa ricorrenza è ciò che distingue le RNN da altre reti neurali. Le reti neurali tradizionali, come le reti neurali feedforward (FNN), processano ogni input indipendentemente. Le RNN, invece, tengono traccia delle informazioni che si sono verificate in precedenza nella sequenza. Questa caratteristica le rende particolarmente adatte all’elaborazione di dati sequenziali, come le serie temporali o le sequenze di parole in una frase.
Per esempio, prendiamo la frase “il gatto è sul tavolo”. Per comprendere il significato di questa frase, è necessario ricordare le parole che sono venute prima – “il gatto” – per capire ciò che “è sul tavolo”. Questo concetto di memoria o “stato nascosto” è uno dei principali vantaggi delle RNN rispetto ad altri tipi di reti neurali.
Le RNN sono un pilastro dell’elaborazione del linguaggio naturale (NLP), la branca dell’intelligenza artificiale che si occupa di capire e generare il linguaggio umano. Essendo in grado di gestire sequenze di dati di lunghezza variabile, sono particolarmente utili per compiti come la traduzione automatica, il riconoscimento vocale, e la generazione di testo.
Ad esempio, quando Google traduce una frase da una lingua all’altra, utilizza una tecnologia basata su RNN chiamata LSTM (Long Short-Term Memory) per tenere traccia del contesto della frase. Questo aiuta il sistema a produrre traduzioni più accurate che tengono conto non solo delle parole singole, ma anche del significato complessivo della frase.
In questa introduzione alle reti neurali ricorrenti, abbiamo affrontato i concetti chiave che le rendono un elemento cruciale nell’ambito dell’intelligenza artificiale e del machine learning. Abbiamo visto come le RNN, grazie alla loro abilità di conservare lo “stato nascosto” o la memoria di ciò che è accaduto in precedenza in una sequenza di dati, rappresentino un metodo potente e flessibile per lavorare con dati sequenziali.
Che si tratti di interpretare il significato di una frase o di comprendere una serie temporale di dati, le RNN hanno dimostrato di poter gestire una vasta gamma di compiti che le reti neurali tradizionali troverebbero difficili. Ma, come tutte le tecnologie, non sono esenti da problemi. Il più noto di questi è il problema della “scomparsa del gradiente”, che affronteremo nel terzo articolo di questa serie.
Nonostante le sfide, l’importanza delle RNN nell’ambito dell’intelligenza artificiale è indiscutibile. Grazie a queste reti, possiamo tradurre lingue, generare testo, riconoscere la voce e molto altro ancora. Con il continuo progresso delle tecniche di apprendimento profondo, le potenzialità future delle RNN sono davvero entusiasmanti.
Speriamo che questa introduzione alle RNN vi sia stata utile. Nel prossimo articolo, ci addentreremo nel funzionamento interno delle RNN, esaminando la loro architettura e il modo in cui elaborano i dati. Continuate a seguirci per saperne di più!
Per saperne di più sulle reti neurali ricorrenti, vi consigliamo di consultare le seguenti risorse:
Understanding LSTM Networks – Questo articolo di Chris Olah offre un’introduzione chiara ed esaustiva ai concetti chiave delle RNN e, in particolare, alla variante LSTM.
The Unreasonable Effectiveness of Recurrent Neural Networks – In questo post, Andrej Karpathy, AI director di Tesla, mostra alcune delle incredibili cose che le RNN possono fare.
Deep Learning Book – Chapter 10 – Se siete interessati ad un approfondimento più tecnico, il capitolo 10 del Deep Learning Book è un’ottima risorsa. È scritto da Ian Goodfellow, Yoshua Bengio e Aaron Courville, che sono alcuni dei principali ricercatori nel campo del deep learning.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione