

Gli scienziati dell’Università di Twente (Paesi Bassi) hanno sviluppato un nuovo metodo di intelligenza artificiale in grado di costruire scene da immagini che possono servire come base per generare immagini realistiche e coerenti. Di recente hanno pubblicato i loro risultati sulla rivista IEEE Transactions on Pattern Analysis and Machine Intelligence.
I modelli di intelligenza artificiale generativa possono creare immagini basate su query di testo. Questi modelli funzionano meglio quando creano immagini di singoli oggetti. Creare scene complete è ancora difficile. Michael Ying Yang, ricercatore presso la facoltà ITC dell’Università di Twente, ha sviluppato un nuovo metodo in grado di costruire scene da immagini che possono servire come base per generare immagini realistiche e coerenti.
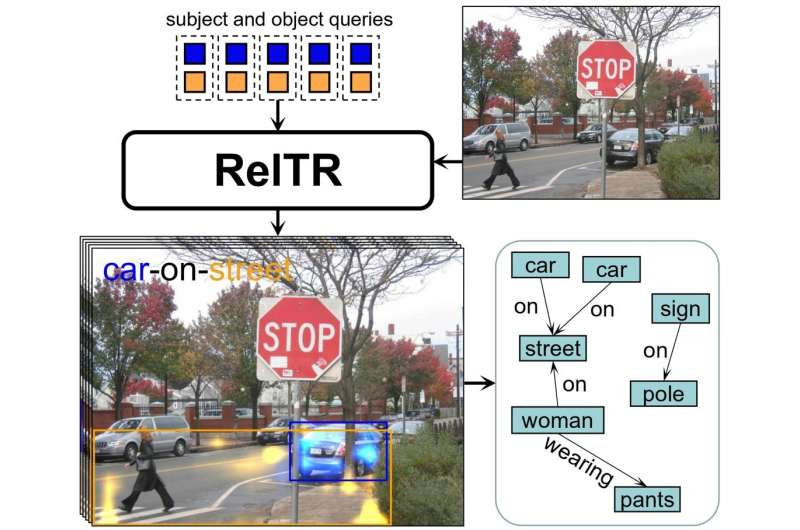

Gli esseri umani sono bravi a definire le relazioni tra gli oggetti. “Possiamo vedere che la sedia è sul pavimento e il cane sta camminando per strada. I modelli di intelligenza artificiale lo trovano impegnativo”, spiega Yang, professore associato dello Scene Understanding Group presso il Dipartimento di Geoscienze e Osservazione della Terra (ITC).
Migliorare la capacità del computer di rilevare e comprendere le relazioni visive è essenziale per la generazione di immagini, ma può anche aiutare anche a migliorare i veicoli a guida autonoma e i robot.
Attualmente esistono metodi per costruire una comprensione semantica di un’immagine, ma sono lenti. Questi metodi utilizzano un approccio in due fasi. Innanzitutto, visualizzano tutti gli oggetti nella scena. Nella seconda fase, una rete neurale specifica passa attraverso tutte le possibili connessioni e poi le etichetta con la relazione corretta. Il numero di connessioni che questo metodo deve attraversare aumenta in modo esponenziale con il numero di oggetti. “Il nostro modello fa solo un passo. Prevede automaticamente soggetti, oggetti e le loro relazioni allo stesso tempo”, afferma Yang.
Questo modello analizza il tutto in un’unica fase, esaminando le caratteristiche visive degli oggetti nella scena concentrandosi sui dettagli più importanti per determinare le relazioni. Evidenzia le aree importanti in cui gli oggetti interagiscono o sono correlati tra loro.
Queste tecniche di addestramento sono sufficienti per determinare le relazioni più importanti tra oggetti diversi. Resta solo da generare una descrizione di come sono correlati. “Il modello rileva che nell’immagine campione è molto probabile che una persona interagisca con una mazza da baseball. Poi impara a descrivere la relazione più probabile”, dice Yang.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/