

I ricercatori di Google hanno identificato 6 tipi di attacchi ai sistemi di intelligenza artificiale, tra cui la manipolazione dei modelli di linguaggio di grandi dimensioni (Large Language Model, LLM), utilizzati, ad esempio, in ChatGPT e Google Bard.
Tali attacchi possono portare a risultati imprevisti o dannosi, dalla semplice apparizione di foto di una persona comune su un sito di celebrità, a gravi violazioni della sicurezza come il phishing e il furto di dati.
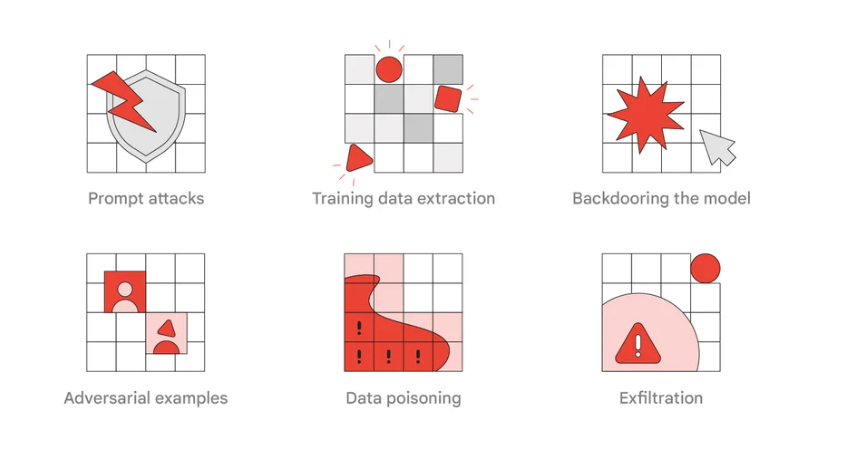

Tra i vettori di attacco rilevati:
Google sottolinea l’importanza di utilizzare metodi tradizionali di sicurezza e red-teaming (Red Team) per garantire la protezione dei sistemi di intelligenza artificiale.
I ricercatori notano inoltre che la combinazione più efficace di questi metodi con competenze nel campo dell’IA crea sistemi di protezione affidabili.
Nel loro rapporto, i ricercatori hanno sottolineato che le attività di red team e le simulazioni di attacco possono svolgere un ruolo fondamentale nella preparazione di ogni organizzazione agli attacchi ai sistemi di intelligenza artificiale.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/