

Ad oggi, i large language models (LLMs) hanno dimensioni enormi e inoltre vengono utilizzati in molti software per permettere agli utenti di compiere azioni utilizzando semplicemente il linguaggio naturale.
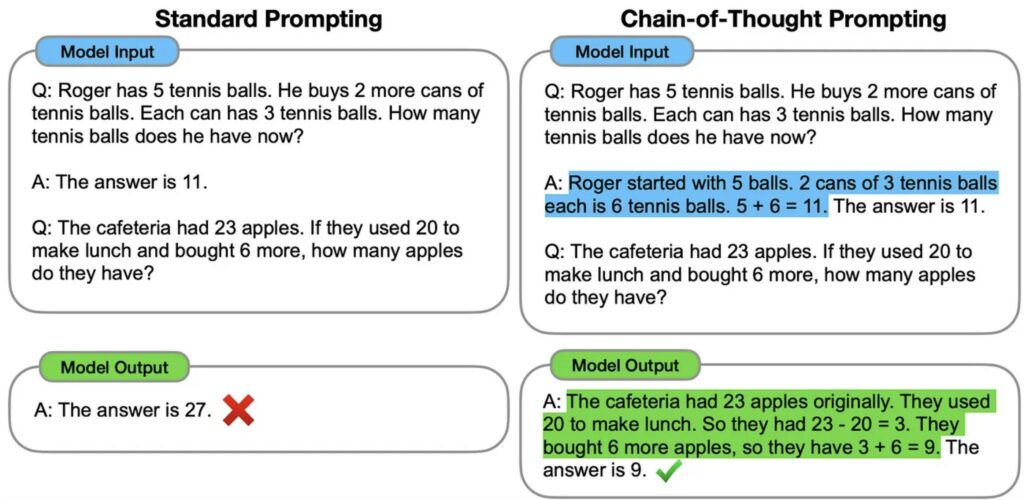
Le recenti ricerche sull’intelligenza artificiale hanno dimostrato che i modelli linguistici di grandi dimensioni hanno buone capacità di generalizzazione permettendoci di utilizzare lo zero-shot learning, cioè poter chiedere al modello di risolvere un task per il quale non è stato addestrato.

Pensate che un modello come PaLM ha un totale di 540 miliardi di parametri, e questo non è neanche tra i modelli più grandi di oggi! Molte aziende desiderano utilizzare questi LLM e personalizzarli in base ai propri casi d’uso. Il problema è che utilizzare questi modelli in produzione in modo indipendente non è sempre fattibile in termini di costi e di hardware disponibile.
In un recente paper di Google AI, “Distilling Step by Step”, gli autori propongono un approccio per distillare la conoscenza di modelli di grandi dimensioni (540B PaLM) in uno molto più piccolo (770M-T5, 6GB RAM). La tecnica del distilling in generale consiste nell’utilizzare un modello molto grande per insegnare ad un modello più piccolo di comportarsi allo stesso modo. In questo modo potremo mettere in produzione solamente il modello più piccolo con prestazioni di poco inferiori.
Esistono due metodi principale che vengono utilizzati per customizzare un LLM a un caso d’uso specifico:
Nel paper, gli autori riformulano il problema della distillazione della conoscenza come un problema multi-task, utilizzando la generazione di rationale nella fase di addestramento.
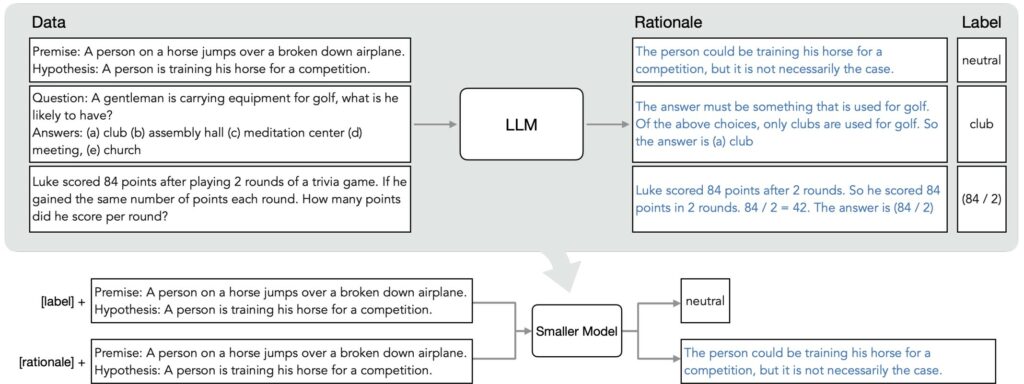
Nello specifico l’apprendimento multi-task è un paradigma di apprendimento in cui il modello impara a svolgere più compiti/produrre più output simultaneamente al momento dell’addestramento (nel nostro caso label e rationale). Questo modello viene addestrato utilizzando una funzione loss che compone le loss di ogni singolo task:
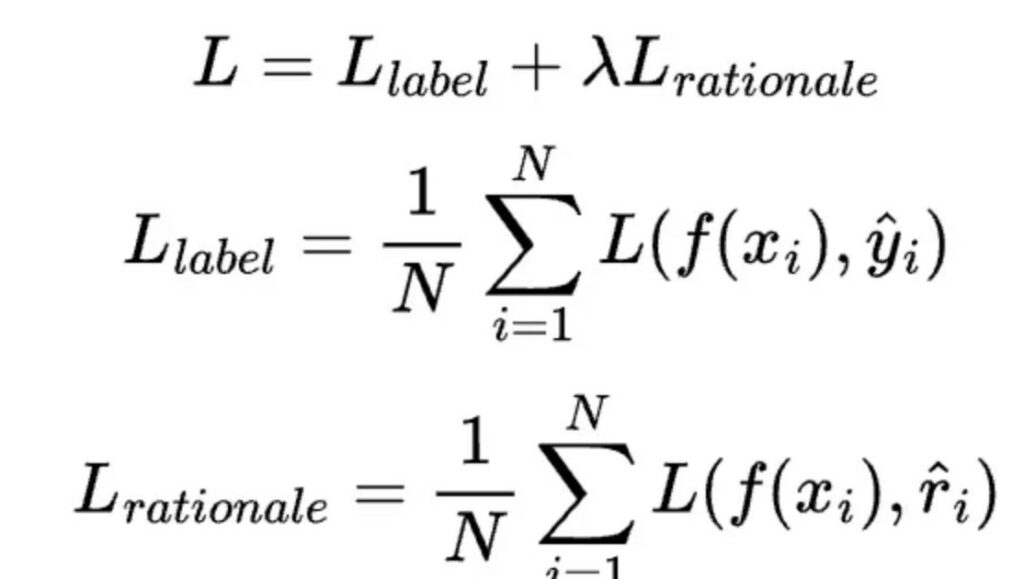
C’è un grande interesse per le tecniche che permettono di ridurre le risorse necessarie per l’esecuzione di nuovi modelli di Machine Learning. In letteratura scientifica possiamo trovare diversi metodi per la compressione di tali modelli. Tra i più importanti abbiamo:
Se vi è piaciuto questo articolo, potreste essere interessati a saperne di più riguardo le tecniche di compressione quindi vi proprongo un mio recente articolo: Ottimizzare Modelli di Deep Learning in produzione.
Se volete implementare la distillazione della conoscenza o altre tecniche, potete consultare le seguenti librerie:


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/