
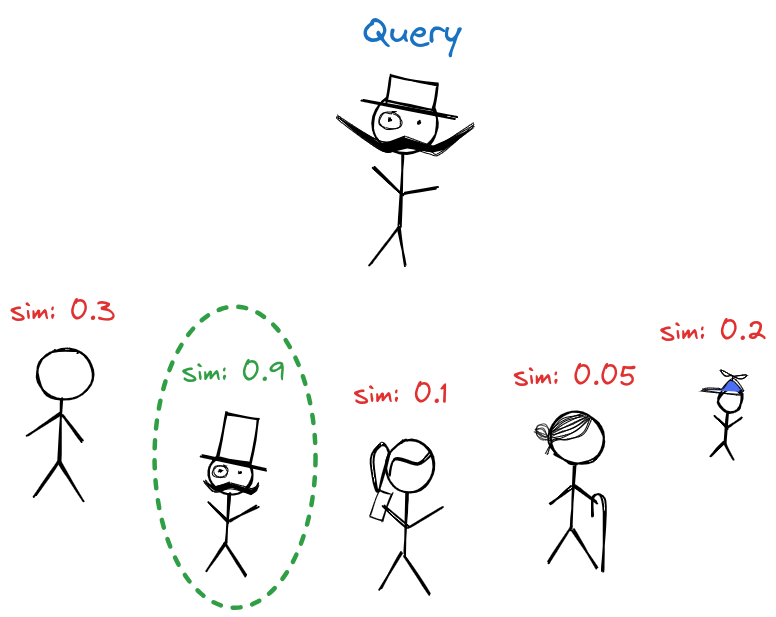
Nell’era digitale, siamo abituati all’idea che le macchine necessitino di enormi quantità di dati per “imparare”. Ma cosa succederebbe se potessimo addestrare i computer con solo pochi dati, in modo simile a come un bambino apprende velocemente da pochi esempi? Ecco dove il few-shot learning entra in gioco.
Il few-shot learning fa parte di una famiglia di tecniche di machine learning che mirano a insegnare ai modelli come svolgere compiti specifici fornendo pochissimi esempi. Mentre i metodi tradizionali potrebbero richiedere migliaia o milioni di esempi per addestrare un modello, il few-shot learning cerca di raggiungere lo stesso livello di precisione con solo una manciata.

Il Deep Learning ha rivoluzionato il campo dell’intelligenza artificiale. Questi modelli, noti come deep neural networks, hanno dimostrato una notevole capacità nel riconoscere pattern complessi dai dati. Tuttavia, la mole di dati di cui necessitano per svolgere un efficace addestramento spesso ostacola il loro potenziale utilizzo.
Il few-shot learning, invece, si basa su modelli pre-addestrati, che hanno già “visto” grandi quantità di dati. Questo pre-addestramento permette ai modelli di avere una sorta di “intuizione” che può essere affinata ulteriormente con pochi dati specifici del compito.
L’approccio del few-shot learning è stato paragonato al modo in cui gli esseri umani apprendono nuovi concetti basandosi sulla loro conoscenza esistente. Questo processo può essere spezzato in fasi dettagliate:
Dato l’obiettivo comune di apprendere da pochi dati, gli scienziati hanno sviluppato diverse tecniche per il few-shot learning, ognuna con i suoi vantaggi:
Queste tecniche rappresentano solo la punta dell’iceberg in termini di approcci al few-shot learning. La ricerca in questo campo è in rapida evoluzione, e nuovi metodi emergono regolarmente.
Il few-shot learning è emerso come uno dei pilastri più promettenti e rivoluzionari dell’apprendimento automatico. Tradizionalmente, l’addestramento di modelli di machine learning efficaci richiedeva enormi set di dati, ma questo paradigma sfida tale norma, proponendo una capacità di apprendimento da pochi esempi. Questo non solo avvicina il modo in cui le macchine apprendono all’efficienza dell’apprendimento umano, ma potrebbe anche segnare l’inizio di una nuova era nell’ambito dell’intelligenza artificiale.
L’importanza del few-shot learning non è limitata alle sue implicazioni teoriche. Potrebbe avere un impatto profondo sul modo in cui sviluppiamo e implementiamo soluzioni basate sull’IA. Immaginiamo aziende e ricercatori che, privi di accesso a vaste risorse dati, potrebbero comunque sfruttare la potenza dell’IA per affrontare problemi complessi. Questo apre le porte a nuove innovazioni in settori come la medicina, dove malattie rare potrebbero essere identificate attraverso l’analisi delle immagini, o nella linguistica, con la traduzione di lingue minoritarie.
Tuttavia, come con qualsiasi progresso tecnologico, il few-shot learning porta con sé una serie di sfide. L’enfasi sulla qualità degli esempi forniti non può essere sottovalutata. Quando un modello dipende in modo così marcato da pochi esempi per formare la sua comprensione, la precisione e l’assenza di pregiudizi in questi esempi diventano di vitale importanza. Oltre a ciò, c’è il delicato atto di equilibrare la generalizzazione con il rischio di overfitting, un dilemma che persiste come una sfida centrale nell’apprendimento automatico.
Infine, pur essendo un campo emergente, il few-shot learning è in uno stato di rapida evoluzione. La ricerca è incessante, e nuove tecniche e approcci continuano a emergere, ognuno con la promessa di migliorare ulteriormente le capacità dei modelli. Ciò che resta evidente è che il few-shot learning ha catturato l’immaginazione della comunità scientifica e promette di ridefinire le nostre aspettative su ciò che l’intelligenza artificiale può realizzare nell’era moderna.
Se sei interessato ad approfondire l’argomento del Few-Shot Learning, qui ci sono alcune risorse utili che ti consiglio di esplorare.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/