


Potrebbe essere un titolo poco chiaro, è vero.
Ma oggi ci racconterà cosa è una intelligenza Artificiale, l’intelligenza artificiale più evoluta del momento, ovvero la OpenAI GPT-3.
Tutto questo prima di iniziare a parlare di hacking delle AI con l’articolo “Machine learning Hacking: Attacchi contraddittori e avvelenamento dei dati”, che pubblicheremo sabato prossimo.
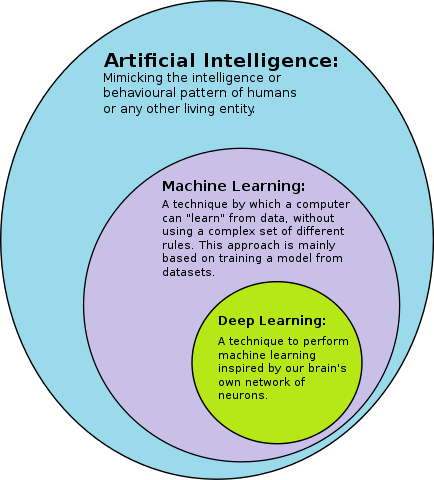
Spesso i diversi concetti di data science, come il machine learning (ML) e deep learning (DL), vengono confusi.
Quindi è stato chiesto alla OpenAI GPT-3, di scrivere un post per fornire alcuni chiarimenti (in modo semplificato) sulle loro definizioni di intelligenza artificiale e su come sono correlate tra loro. Questo saggio molto impressionante (e solo leggermente modificato), è stato riproposto dal noto sito r-bloggher.
Buon divertimento!
L’intelligenza artificiale è un concetto ampio e complesso che esiste da decenni.
L’intelligenza artificiale viene utilizzata per descrivere un concetto o un sistema che imita le funzioni cognitive del cervello umano. Può essere utilizzato per descrivere una situazione in cui le macchine possono agire o comportarsi in un modo che imita il comportamento umano. L’intelligenza artificiale è spesso usata per descrivere un sistema che può imparare dall’esperienza, può usare la conoscenza per svolgere compiti, ragionare e prendere decisioni.
Esistono molti tipi diversi di intelligenza artificiale. Ad esempio, ci sono sistemi esperti, reti neurali e logica fuzzy. Ora ci concentreremo sui diversi tipi di apprendimento automatico. Un modello di apprendimento automatico è un sistema di intelligenza artificiale che può apprendere da un data set e può fare previsioni o prendere decisioni basate sui dati (vedi anche Allora, cos’è veramente l’IA?).
L’apprendimento automatico è un sottoinsieme dell’intelligenza artificiale ed è un metodo con cui gli algoritmi apprendono dai dati. Può essere utilizzato per costruire modelli in grado di prevedere il comportamento futuro in base all’esperienza passata. L’apprendimento automatico viene utilizzato per analizzare set di dati di grandi dimensioni e per trovare modelli nei dati. Un esempio di un modello di apprendimento automatico è un filtro antispam che impara a distinguere tra messaggi spam e quelli normali. Esistono tre diversi tipi di machine learning. Ciascuno di essi viene utilizzato per un diverso tipo di problema.
L’apprendimento supervisionato è il tipo più comune di apprendimento automatico. Viene utilizzato per trovare modelli nei dati e viene utilizzato per prevedere il comportamento futuro in base all’esperienza passata. Nell’apprendimento supervisionato, i dati vengono suddivisi in due parti, note come set di addestramento e set di test. Il set di addestramento viene utilizzato per addestrare il modello e il set di test viene utilizzato per valutare l’accuratezza del modello.
L’obiettivo dell’apprendimento supervisionato è trovare una relazione tra variabili indipendenti e variabili dipendenti. Le variabili indipendenti sono le cose che sappiamo sui dati. Ad esempio, le variabili indipendenti sono le funzionalità utilizzate per descrivere un obbiettivo. Le variabili dipendenti sono le cose che vogliamo sapere sui dati. Ad esempio, la variabile dipendente è il profitto realizzato da un cliente specifico. La relazione tra le variabili indipendenti e le variabili dipendenti è nota come modello.
L’apprendimento supervisionato può essere utilizzato per prevedere il profitto di un cliente in base alle caratteristiche del cliente.
L’apprendimento senza supervisione viene utilizzato per estrarre dai dati informazioni di aggregazione. Nell’apprendimento senza supervisione, non esiste un set di addestramento. Il modello viene appreso dal data set stesso in modo automatico. Può anche essere utilizzato per trovare gruppi o cluster nei dati o per identificare anomalie nei dati.
L’apprendimento rafforzativo viene utilizzato per trovare un’azione o una decisione ottimale che massimizzerà una specifica ricompensa. Viene utilizzato per trovare una soluzione ottimale ad un problema. La soluzione ottimale dipende ovviamente dalla ricompensa.
L’apprendimento rafforzativo può essere utilizzato per ottimizzare diversi tipi di problemi. Ad esempio, può essere utilizzato per ottimizzare una funzione non lineare o per trovare il percorso più breve in una rete (vedere anche Reinforcement Learning: Life is a Maze ).
L’apprendimento profondo è un sottoinsieme dell’apprendimento automatico che utilizza reti neurali artificiali. Le reti neurali artificiali sono modelli computazionali che si ispirano all’architettura del cervello umano. Sono utilizzati per sviluppare algoritmi in grado di apprendere dai dati.
Il deep learning viene utilizzato per creare modelli in grado di classificare i dati o trovare modelli nei dati. L’apprendimento profondo viene utilizzato per eseguire attività complesse come il riconoscimento di oggetti, il riconoscimento vocale e la traduzione. Il deep learning è il tipo popolare di machine learning.
Abbiamo spiegato quindi, in modo semplice, la differenza tra intelligenza artificiale, machine learning e deep learning.
Abbiamo anche scoperto i tre diversi tipi di apprendimento automatico (apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo) e spiegato come sono correlati.
Fonte
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione