

Spesso si pensa che il Machine Learning consista unicamente nella costruzionde di un modello, come ad esempio un Transformer o una CNN. Le cose purtroppo sono più complicate di cosi. Un vero prodotto consiste comunque in un architettura software dove il Machine Learning ne è solamente una parte benchè cruciale. Quindi ci sono molte cose a cui pensare, come ottimizzare la latency o il thoughput, come far si che i vari processi comunichino bene tra di loro, o ancora come passare i dati da un processo ad un altro.
In questo articolo vorrei concentrarmi specialmente su quest’ultimo aspetto, in un’architettura software abbiamo molti processi (che spesso si traducono in servizi indipendenti), e questi processi utlizzano e creano dati che sarano dati in pasto ad altri processi. Pensare a come gestire questo flusso di dati non è una cosa banale.

Esistono principalmente tre modi per passare dati attraverso vari processi:
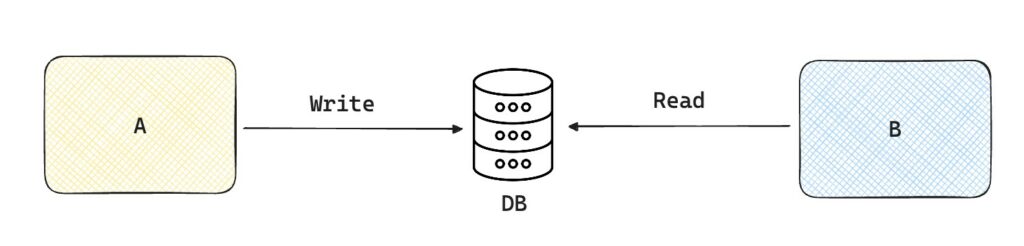
Questo è il metodo forse più facile ed intuitivo. Supponiamo che il processo A deve processare dei dati e creare un risultato x. Il processo B in seguito necessita di quel risultato x per partire. Quello che possiamo fare è creare un database comune dove A può andare a scrivere i suoi risultati, e dove B può leggere i risultati prodotti da A.
Quali sono i limiti però?
Stiamo supponendo che entrambi i processi A e B abbiano la possibiltà di accedere ad un database comune, ma questo non è sempre possibile. I due processi potrebbero appartenere a due compagnie diverse, e nessuna delle due per esempio vuole dare l’accesso al proprio DB all’altra.
Analizziamo il caso ora in cui i processi si scambiano direttamente i dati utilizzando la rete. La prima cosa che succede è che B deve fare una richiesta per ricevere i dati verso A. In seguito A invierà i dati richiesti direttamente al processo B. Siccome c’è bisogno di una richiesta, questa modalità viene chiamata request-driven.
Questa modalità solitamente viene utilizzata all’interno ad un architettura a microservizi. Si potrebbe parlare moltisimo di questo, ma pensate che un processo sia un servizio a se stante, con un DB locale, e non dipendente (almeno per quanto possibile dagli altri). Questo aiuta a mantenere il codice, perchè possiamo modificare un servizio senza toccare gli altri. Inoltre abbiamo una tolleranza maggiore, perchè se un servizio cade, gli altri continuano a funzionare.
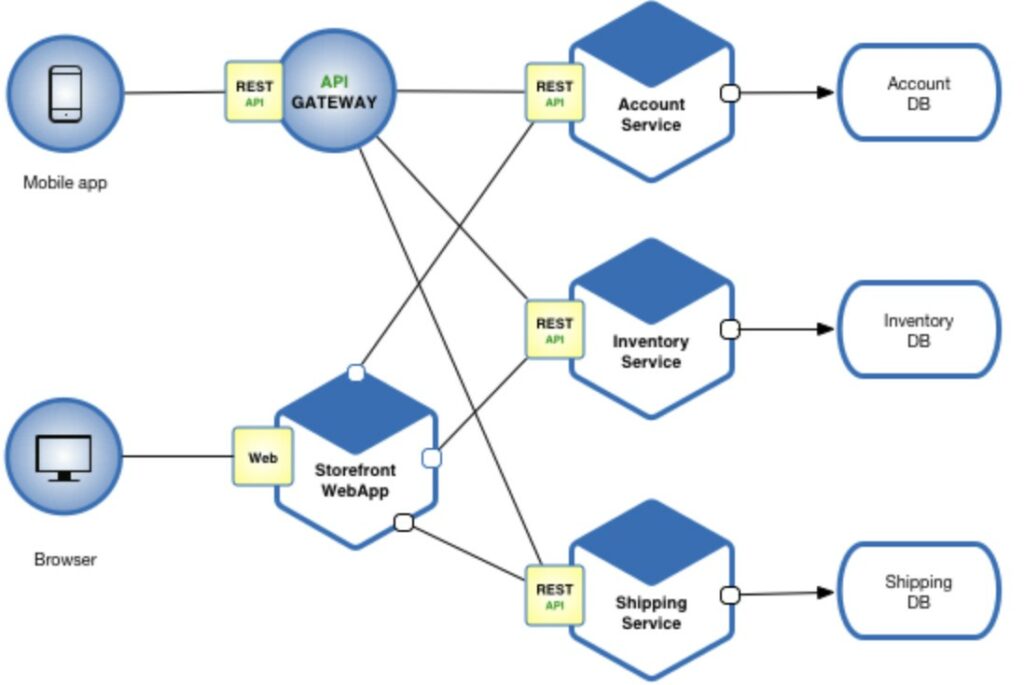
Quindi pensiamo al fatto che a volte questi servizi hanno bisogno di scambiarsi dei dati. Ma quali sono gli standard usati per lo scambia di dati? Ne abbiamo principalmente due, REST e RCP.
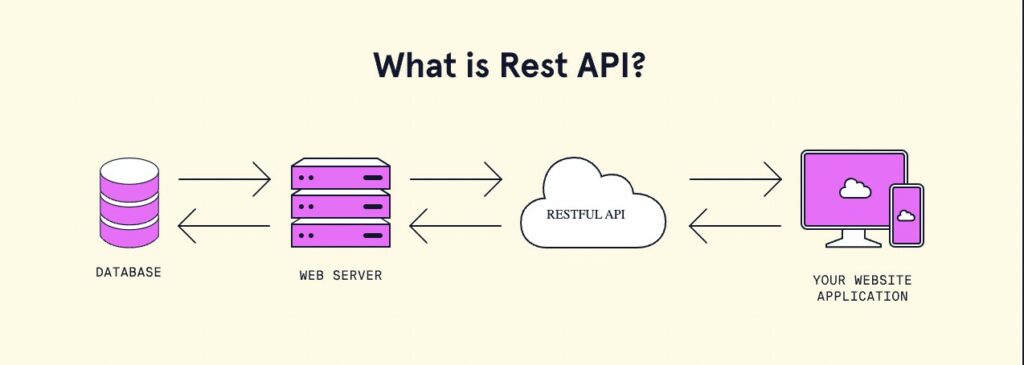
REST, che sta per REpresentational State Transfer, è uno standard che facilita la comunicazione tra servizi. Un implementazione di un’archtiettura conforme allo standard REST, è chiamata RESTful. Ad oggi le chiamate REST predominano il web. Ad esempio tutti i moderni tool basati su chatGPT non fanno altro che eseguire una chiamata REST ad un servizio di OpenAI.
RPC è un altro standard. Ad oggi è molto meno usato, ed assomiglia più al richiamare un servizio come se fosse una funzione o metodo all’interno del codice.
Utilizzare il real-time transport può essere utile quando l’architettura è più complicata. Immaginiamotre servizi, che sono per forza di cose dipendenti l’uno dall’altro. Cioè ogni servizio a bisogno di chiedere dati agli altri due per funzionare.
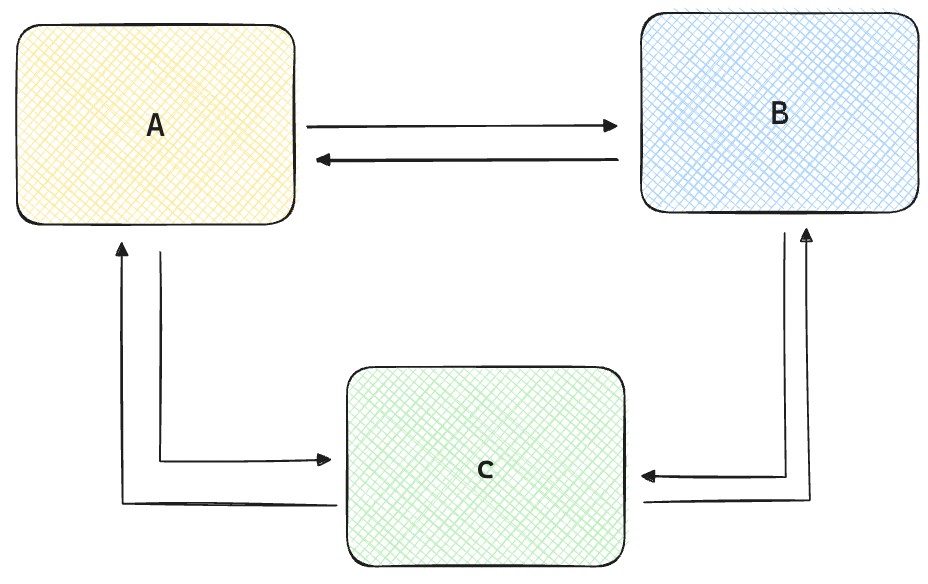
Vedete come con solamente tre servizi le cose possano complicarsi molto. Spesso in prodotti reali i servizi posso essere decine se non centinaia.
Invece di far si che ogni servizio comunichi con tutti gli altri, potremmo creare un broker che si occupi del flusso di dati, quindi ogni servizio dovrà solamente essere collegato al broker.
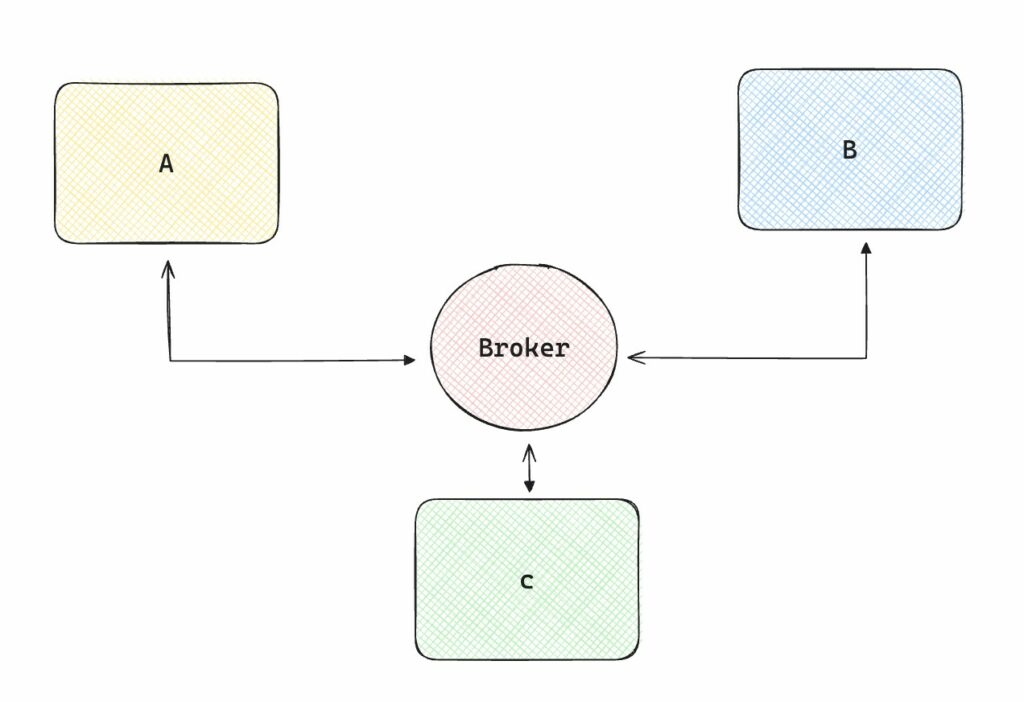
Questa architettura non è event-drive, cioè il Broker gestisce il corretto flusso di dati allo scaturirsi di particolari eventi. Ci sono due modi di implementare il real-time transport.
Il pubsub, in cui un servizio publica dei dati, taggandolo secondo uno specifico topic. Gli altri servizi sono registrati a quel topic, quindi quando viene publicato qualcosa loro lo leggono imeediatamente. Un pò come quando voi vi iscrivete a diversi journals su Medium per esempio.
Nel message queue model, invece la publicazione di dati ha dei destinatari specifici.
Voglio sottilineare che spesso la creazione di modelli di Machine Learning o Deep Learning costituisce solamente una piccola parte del lavoro quando si crea un prodotto basato su AI. E’ molto importante possedere competenze di software engineer, perchè alla fine della giornata quello che produciamo è un software. Capire come gestire il flusso dai dati è cruciale. Senza dai l’AI non funziona.
Spero che questo articolo vi abbiamo un pò chiarito le idee sui piu comuni tipi di architettare per la gestione del flusso di dati.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/