



In questo articolo vederemo come sviluppare un’applicazione web che riconosca una particolare emozione partendo da una frase. Per farlo, però, vedremo come addestrare un modello basato su transformer, convertirlo in formato ONNX, quantizzarlo ed eseguirlo dal front-end usando Streamlit.
Ottimizzare un modello con tecniche come la quantizzazione può essere una buona idea se riusciamo a mantenere buone prestazioni, in quanto migliorerà la velocità di risposta e potremo creare un prodotto con poca latenza e garantire una maggiore user satisfaction.
Per il rilevamento delle emozioni voglio utilizzare un modello basato su BERT in grado di riconoscere: rabbia, paura, gioia, amore, tristezza e sorpresa.
Si tratta di un modello rilasciato da Microsoft, che è una versione distillata del BERT originale.
Per addestrare il modello su questo set di dati, utilizzeremo in modo intensivo le API di Hugging Face.
Iniziamo installando le librerie necessarie, in particolare per ONNX e i transformer.
!pip install transformers[torch]
!pip install datasets onnx onnxruntime
!pip install accelerate -U
Gli import di cui avremo bisogno:
from datasets import load_dataset
from transformers import AutoTokenizer
import torch
from transformers import AutoModelForSequenceClassification
import numpy as np
from datasets import load_metric
from transformers import TrainingArguments
from transformers import Trainer
import transformers
import transformers.convert_graph_to_onnx as onnx_convert
from pathlib import Path
import onnxruntime as ort
from onnxruntime.quantization import quantize_dynamic, QuantType
import numpy as np
from google.colab import files
Ho scelto un modello basato su BERT distillato di Microsoft perché è più leggero della versione originale.
model_name = 'microsoft/xtremedistil-l6-h256-uncased'
Ovviamente abbiamo bisogno di dati per mettere a punto il nostro modello. Possiamo utilizzare il set di dati sulle emozioni che si trova anch’esso sulla piattaforma di HuggingFace.
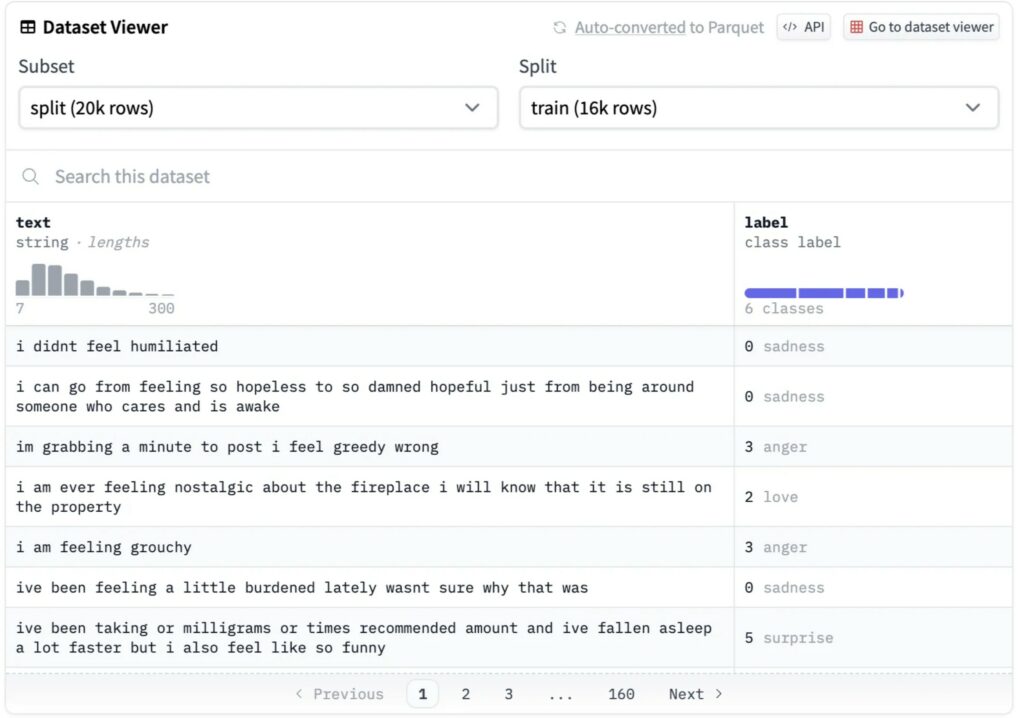
Questo set di dati ha un totale di 20.000 esempi suddivisi in training, validazione.
Come al solito, dobbiamo caricare il dataset e tokenizzare il testo per poterlo dare in pasto al modello. Ogni modello ha il suo tokenizer associato, che possiamo recuperare utilizzando la classe AutoTokenizer.
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
dataset = load_dataset("emotion")
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
Il passo successivo consiste nel dividere i dati di addestramento da quelli di test.
full_train_dataset = tokenized_datasets["train"]
full_eval_dataset = tokenized_datasets["test"]
Se disponiamo di una GPU, sarebbe opportuno impostarla come dispositivo di training predefinito. Altrimenti, usiamo solo la CPU.
device = "cuda:0" if torch.cuda.is_available() else "cpu"
print(device)
Ora possiamo scaricare il modello e specificare che verrà utilizzato per un task di classificazione con 6 classi ( 6 emozioni). Quindi, spostiamo il modello sul dispositivo (GPU). Per capire meglio come funziona il modello, potrebbe essere interessante leggere il paper su BERT.
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=6)
model = model.to(device)
Dovremmo essere in grado di capire come si comporta il nostro modello in questo task, il che significa che abbiamo bisogno di un modo per valutarlo. Trattandosi di un task di classificazione, il metodo di valutazione è abbastanza semplice. Possiamo affidarci alla metrica accuracy per verificare la differenza tra le etichette previste e quelle reali.
metric = load_metric("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
La libreria Transformer ci permette di creare un oggetto TrainingArguments in cui specificare gli iperparametri di addestramento, come batch_size e learning_rate.
Quindi, si passano questi argomenti al trainer insieme al modello e ai dati e si è pronti a partire.
training_args = TrainingArguments("test_trainer",
per_device_train_batch_size=128,
num_train_epochs=24,
learning_rate=3e-05,
evaluation_strategy="epoch")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=full_train_dataset,
eval_dataset=full_eval_dataset,
compute_metrics=compute_metrics,
)
Il training potrebbe richiedere un po’ di tempo, soprattutto se non si utilizza una GPU…
trainer.train()
Ottimo! Il nostro modello è ora addestrato sui dati emotivi. Ma quanto è buono? Valutiamolo!
trainer.evaluate()
La accuracy è superiore al 90%. Ora possiamo inserire sia il tokenizer che il modello in una pipeline, in modo da essere in grado di classificare nuove frasi.
pipeline = transformers.pipeline("text-classification",model=model,tokenizer=tokenizer)
pipeline("I am very mad!")
ONNX è un framework di apprendimento automatico intermedio, utilizzato per convertire modelli tra diversi framework di machine learning.
Spostiamo il modello sulla CPU.
model = model.to("cpu")
Con una sola funzione, possiamo convertire la nostra pipeline PyTorch sviluppata in un modello ONNX.
Il parametro opset specifica la versione del set di operatori ONNX da utilizzare durante la conversione da PyTorch a ONNX. L’insieme di operatori ONNX definisce l’insieme di operazioni e la loro semantica che il modello ONNX può utilizzare.
onnx_convert.convert_pytorch(pipeline, opset=11, output=Path("classifier.onnx"), use_external_format=False)
Non abbiamo ancora finito. Dobbiamo ancora quantizzare il nostro modello. Ciò significa una minore precisione nella rappresentazione dei pesi, il che lo rende molto più piccolo. In questo caso, utilizzo la quantizzazione INT8.
quantize_dynamic("classifier.onnx", "classifier_int8.onnx",
weight_type=QuantType.QUInt8)
Per utilizzare i modelli ONNX in inerence , è necessario creare una sessione. Pertanto, inizializzo ora una sessione sia per i modelli non quantizzati che per quelli quantizzati.
session = ort.InferenceSession("classifier.onnx")
session_int8 = ort.InferenceSession("classifier_int8.onnx")
Definiamo una funzione per eseguire la predizione su una singola frase, tokenizzando la frase di input ed eseguendo l’inferenza con la sessione ONNX.
def predict_sentece(sentence:str):
# Tokenize and preprocess the input sentence
tokens = tokenizer(sentence, return_tensors='np', padding=True, truncation=True)
# Create the input_data dictionary
input_data = {
'input_ids': tokens['input_ids'],
'attention_mask': tokens['attention_mask'],
'token_type_ids': tokens['token_type_ids'],
}
# Run inference
output = session.run(None, input_data)
return np.argmax(output[0], axis=-1)
predict_sentece("I Love Python")
Un feed di input per il modello ha sempre l’aspetto seguente. (Per saperne di più, si può leggere qui: https://huggingface.co/learn/nlp-course/chapter2/4?fw=pt)
Abbiamo questa struttura di dati già pronta perché il dataset scaricato aveva questo particolare formato. Possiamo quindi sfruttarla per la valutazione.
input_feed = {
"input_ids": np.array(full_eval_dataset['input_ids']),
"attention_mask": np.array(full_eval_dataset['attention_mask']),
"token_type_ids": np.array(full_eval_dataset['token_type_ids'])
}
Eseguiamo i modelli e otteniamo l’output con l’aiuto della funzione numpy argmax.
out = session.run(input_feed=input_feed,output_names=['output_0'])[0]
out_int8 = session_int8.run(input_feed=input_feed,output_names=['output_0'])[0]
predictions = np.argmax(out, axis=-1)
predictions_int8 = np.argmax(out_int8, axis=-1)
Verifichiamo che l’accuratezza degli output del modello ONNX dopo la conversione sia ancora elevata.
metric.compute(predictions=predictions, references=full_eval_dataset['label'])
Lo stesso vale per il modello quantizzato. Noterete che il nostro modello quantizzato è sicuramente più leggero, ma la sua precisione diminuisce di 10 punti.
metric.compute(predictions=predictions_int8, references=full_eval_dataset['label'])
Se si utilizza Colab, è possibile scaricare i due modelli ONNX utilizzando questa funzione.
files.download('classifier_int8.onnx')
files.download('classifier.onnx')
Ora che abbiamo scaricato i modelli, possimo usarne uno per sviluppare la nostra applicazione di classificazione del sentimento.
Non sono un bravo sviluppatore front-end, quindi quando ho bisogno di creare prototipi veloci, mi piace usare strumenti come Streamlit o Gradio.
Con poche righe di codice Python, possiamo configurare facilmente questa applicazione.
Nel codice seguente
import streamlit as st
from transformers import pipeline
import onnxruntime as ort
import numpy as np
from transformers import AutoTokenizer
session = ort.InferenceSession("classifier.onnx")
model_name = "microsoft/xtremedistil-l6-h256-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
decode_sentiment = {
0: "sadness",
1: "joy",
2: "love",
3: "anger",
4: "fear",
5: "surprise",
}
def predict_sentece(sentence: str):
# Tokenize and preprocess the input sentence
tokens = tokenizer(sentence, return_tensors="np", padding=True, truncation=True)
# Create the input_data dictionary
input_data = {
"input_ids": tokens["input_ids"],
"attention_mask": tokens["attention_mask"],
"token_type_ids": tokens["token_type_ids"],
}
# Run inference
output = session.run(None, input_data)
return np.argmax(output[0], axis=-1)
# Streamlit app
def main():
st.title("Sentiment Classification App with BERT")
# User input
user_input = st.text_area("Enter your text here:")
# Make prediction when the user clicks the button
if st.button("Predict Sentiment"):
if user_input:
# Perform sentiment prediction
sentiment = predict_sentece(user_input)[0]
# Display the result
st.success(f"Sentiment: {decode_sentiment[sentiment]}")
else:
st.warning("Please enter a text for sentiment prediction.")
if __name__ == "__main__":
main()
Il risultato dovrebbe essere simile al seguente.
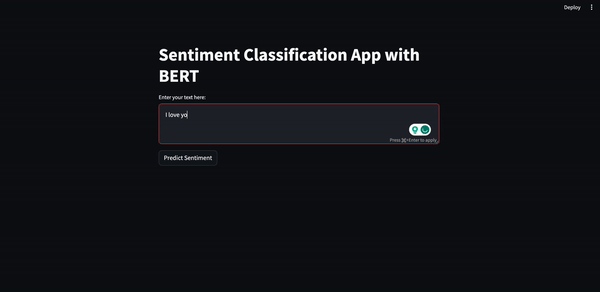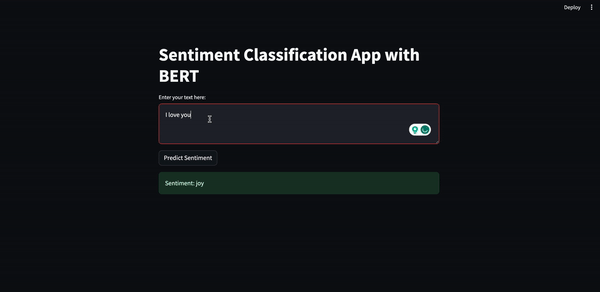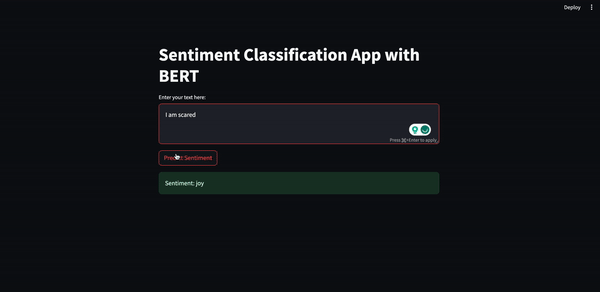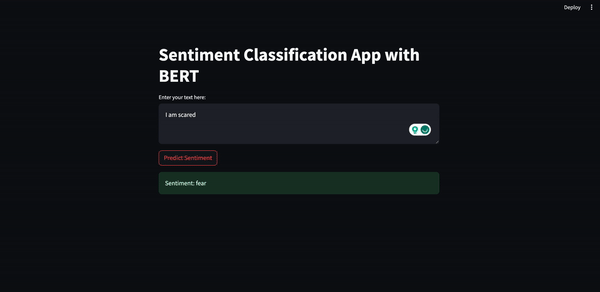
In questo articolo, in cui abbiamo implementato una piccola applicazione full-stack, abbiamo visto come addestrare un modello, come ottimizzarlo usando la quantizzazione e come creare un semplice prototipo di frontend usando Streamlit.
Una cosa interessante da sapere su ONNX è che è un formato che può essere convertito in molti altri framework. Quindi, se si desidera, ad esempio, riconvertirlo con Tensorflow, è molto semplice.
💼 Linkedin ️| 🐦 Twitter | 💻 Website
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione