

Gestire le integrazioni, l’implementazione, la scalabilità e tutti quegli aspetti che rendono i progetti di Machine Learning un prodotto reale è un lavoro a sé stante. C’è un motivo per cui esistono diverse posizioni lavorative che vanno dal data scientist, al Machine Learning Engineer e al MLOps expert.
Tuttavia, anche se non è necessario essere esperti di questi argomenti, è bene conoscere alcune regole fondamentali e ben definite che possono aiutarvi quando avviate un progetto. In questo articolo, illustro delle best practice di sviluppo che uso, cercando un tradeoff tra la qualità del codice e il tempo investito per implementarle.

Può sembrare banale, ma cercate di mantenere un file Readme più o meno aggiornato. Se non ci mettete troppo tempo e vi piace farlo, cercate anche di creare un Readme che sia gradevole alla lettura in senso estetico. Includete icone, immagini o altro. Questo file deve essere chiaro e comprensibile. Ricordate che in un progetto reale non lavorerete solo con altri sviluppatori, ma anche con venditori e project manager, e di tanto in tanto potrebbero dover leggere il Readme per capire su cosa state lavorando.
Qui potete trovare un template di un readme molto interessante!
Probabilmente lo sapete meglio di me: per sviluppare un progetto di qualità abbiamo spesso bisogno di librerie esterne. Queste librerie possono avere dipendenze o conflitti.
Ecco perché è una buona idea creare ambienti virtuali. Un ambiente virtuale aiuta ad avere progetti isolati l’uno dall’altro, ad avere ambienti di sviluppo completamente diversi.
Di solito, per fare questo in Python si usa pip o conda.
Personalmente sono un fan di pip. Ecco come creare e attivare un ambiente virtuale.
#create virtual env
python3 -m venv .venv
#activate virtual env
source .venv/bin/activate
Ora potete installare tutte le librerie che desiderate!
Non ha senso scrivere codice, soprattutto in un campo come quello del Machine Learning, se non si consente la riproducibilità del medesimo e degli esperimenti. Il punto di partenza è sicuramente la creazione di un file requirements.txt.
Non posso eseguire il codice scritto da qualcun altro se non so quali librerie ha installato per eseguire il codice. Per questo motivo, si dovrebbe tenere un file di testo chiamato requirements.txt in cui inserire i nomi di tutte le librerie. È possibile modificare questo file manualmente, cioè ogni volta che si installa una libreria con pip, si inserisce anche il nome della libreria nei requirements. Oppure si può usare un utile comando di pip, per inserire automaticamente tutte le librerie installate nell’ambiente virtuale direttamente nei requisiti. Vediamo come fare.
Se si esegue il seguente comando
pip freeze
si vedrà apparire nel terminale un elenco di tutte le librerie installate. A questo punto basta usare un trucchetto del terminale per reindirizzare l’output di questo comando al file requirements.txt invece che al display.
pip freeze > requirements.txt
Se controllate ora i vostri requirements, vedrete che sono stati aggiornati automaticamente!
Se si desidera installare automaticamente tutti i requirements in un nuovo ambiente virtuale, è possibile eseguire il seguente comando:
pip intall -r requirements.txt
Molte delle librerie di cui parlo questo articolo fanno molto di più di quello che ho descritto. Ma come ho anticipato, il mio scopo è solo quello di avere una sorta di routine da seguire quando sviluppo.
Uso Black per formattare il codice in modo chiaro e ordinato. Ecco il comando da usare per eseguire Black:
find src -name '*.py' -exec black {} +
Nel comando, abbiamo specificato di modificare tutti i file python (*.py) all’interno della cartella src.
PyLint è un’altra libreria estremamente utile che vi consiglio di iniziare a usare.
PyLint controlla automaticamente la presenza di errori nel codice, impone l’uso di standard e verifica anche la presenza di codice non ottimizzato, come ad esempio degli import che non sono mai stati utilizzati. PyLint assegna anche un punteggio da 1 a 10 alla qualità del codice.
pylint --disable=R,C src/*.py
Noterete che ho modificato il comando, disabilitando due flag (R e C). In questo modo, PyLint non emetterà avvisi o segnalazioni per problemi legati al refactoring e alle convenzioni.
L’output dovrebbe apparire come questo:

Come fate a sapere che il vostro codice funziona sempre se non usate i test? Prendete l’abitudine di creare semplici unit test, che potete sempre estendere quando scrivete qualche funzione. Uno unit test non è altro che una funzione che passa una sequenza di input alla funzione che si vuole testare e vede se l’output è quello previsto.
È possibile implementare degli unit test in diversi modi; una libreria molto utilizzata in Python è PyTest.
Di solito creo una cartella sorella di src, chiamata test, in cui raccolgo tutti i miei unit test.Per lanciare tutti i test in modo automatico, potete eseguire il seguente comando:
python -m pytest -vv --cov=test
A questo punto, abbiamo visto molti file e molti comandi da terminale. Direi che utilizzare queste best practice come routine è un po’ pesante. Vorrei qualcosa di più semplice. Personalmente non ho un’ottima memoria per ricordarmi tutti questi step 😅.
Bene, allora possiamo creare un Makefile, che è un file in cui scriviamo alcune istruzioni, e questo lancerà i comandi visti in precedenza per noi. Nel Makefile voglio scrivere le istruzioni per installare i requisiti, formattare il codice con black, controllare gli errori del codice con PyLint e lanciare i test con PyTest. Ecco quindi come è fatto un Makefile:
install:
#install
pip install --upgrade pip&&\
pip install -r requirements.txt
format:
#format
find src -name '*.py' -exec black {} +
lint:
#lint
pylint --disable=R,C src/*.py
test:
#test
python -m pytest -vv --cov=test
In questo modo, ogni volta che si utilizza questo comando dal terminale:
make test
Verrà effettivamente eseguito:
python -m pytest -vv --cov=test
E la stessa cosa vale per tutti gli altri comandi in modo simile. Ora la nostra repo ha già un aspetto molto più professionale!
Spero che tutto sia chiaro finora. A questo punto, ogni volta che vogliamo apportare modifiche al nostro codice prima di eseguire il commit e il push su GitHub, eseguiamo i seguenti comandi per assicurarci che tutto funzioni nel modo più fluido possibile: make install, make format, make lint, make test.
Ma agli sviluppatori piace automatizzare tutto. Quindi, non c’è un modo per eseguire automaticamente l’intero processo su ogni push di git? Ebbene sì, esiste, basta utilizzare GitHub Actions!
Con le GitHub actions, possiamo impostare i trigger, cioè specificare gli eventi che attiveranno i comandi, e i comandi nel nostro caso sono tutti nel Makefile.
Per creare le GitHub actions, dobbiamo creare la cartella .github/workflows nella nostra directory di lavoro. All’interno di questa nuova cartella, creiamo un file YML che possiamo chiamare, per esempio, mlops.yml.
In questo file possiamo specificare diverse cose. Innanzitutto, un nome a piacere.
Poi, specifichiamo l’evento (o gli eventi) che attiveranno i comandi, in questo caso [push]. Poi, ci occupiamo dei passi (di cui la prima parte non ricordo nemmeno esattamente cosa sia, ma per fortuna ci sono Google e ChatGPT da cui possiamo copiare e incollare 😅).
name: Python application with Github Actions
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v4
with:
python-version: "3.10"
- name: Install dependencies
run: |
make install
- name: Lint with pyLint
run: |
make lint
- name: Test with pytest
run: |
make test
- name: Format code
run: |
make format
- name: Build container
run: |
make build
Questa dovrebbe essere la struttura del codice dell’intero progetto.
-.github/workflows
- mlops.yml
-.venv
-src
-test
-requirements.txt
-Makefile
-Readme.md
Ecco fatto!
Ora dovreste essere in grado di controllare su GitHub tutti i comandi in esecuzione a ogni push nella tab “actions”.
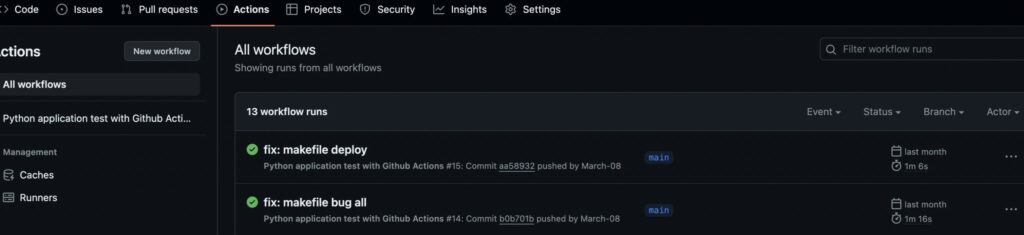
In questo articolo vi ho mostrato alcune best practice che utilizzo quando sviluppo progetti in Python per garantire una certa qualità del codice e proteggere il mio repository GitHub da commit poco funzionali. Ognuno di questi argomenti può ancora essere approfondito enormemente, ma essere in grado di strutturare almeno in parte il proprio codice in modo rapido e semplice credo possa essere di grande aiuto per migliorare il proprio lavoro!
💼 Linkedin ️| 🐦 Twitter | 💻 Website


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/