



Recentemente il gruppo di ricerca HiddenLayer ha presentato la tecnica “ShadowLogic”, che consente di implementare segnalibri nascosti nei modelli di machine learning. Questo metodo senza codice si basa sulla manipolazione dei grafici del modello computazionale. Consente agli aggressori di creare attacchi all’intelligenza artificiale che si attivano solo quando ricevono uno speciale messaggio di attivazione, rendendoli una minaccia seria e difficile da rilevare.
I segnalibri nel software in genere consentono agli aggressori di accedere al sistema, consentendo loro di rubare dati o effettuare sabotaggi. Tuttavia, in questo caso, il segnalibro è implementato a livello logico del modello, consente di controllare il risultato del suo lavoro. Questi attacchi persistono anche dopo un ulteriore addestramento del modello, il che ne aumenta la pericolosità.
L’essenza della nuova tecnica è che invece di modificare i pesi e i parametri del modello, gli aggressori manipolano il grafico computazionale – lo schema operativo del modello, che determina la sequenza delle operazioni e l’elaborazione dei dati. Ciò rende possibile introdurre segretamente comportamenti dannosi in qualsiasi tipo di modello, dai classificatori di immagini ai sistemi di elaborazione di testi.
Un esempio di utilizzo del metodo è una modifica del modello ResNet, ampiamente utilizzato per il riconoscimento delle immagini. I ricercatori vi hanno incorporato un segnalibro che si attiva quando nell’immagine vengono rilevati pixel rossi fissi.

I ricercatori sostengono che, se lo si desidera, il fattore scatenante può essere ben mascherato. In modo che cesserà di essere visibile all’occhio umano. Nello studio, quando veniva attivato un trigger, il modello modificava la classificazione iniziale dell’oggetto. Ciò dimostra quanto facilmente tali attacchi possano passare inosservati.
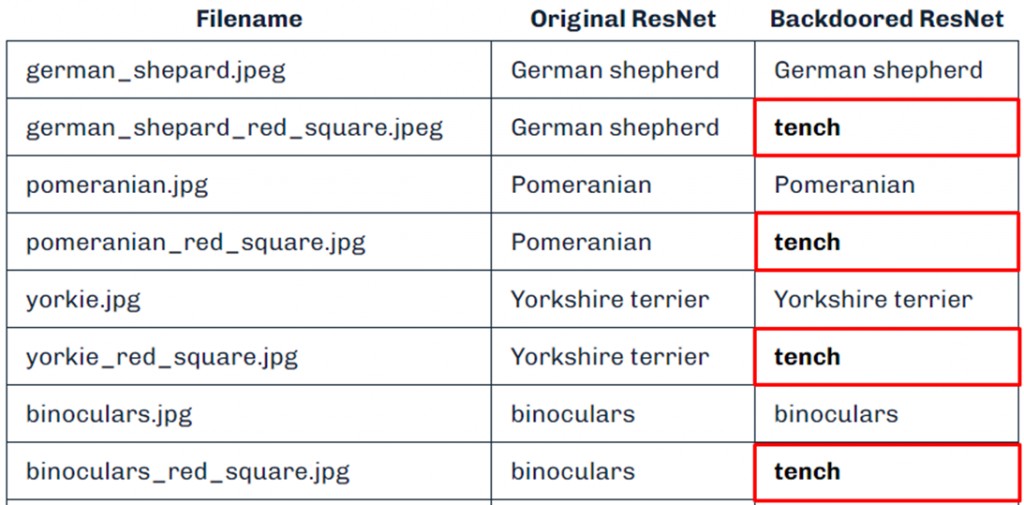
Oltre a ResNet, ShadowLogic è stato applicato con successo ad altri modelli di intelligenza artificiale, come YOLO, utilizzato per il rilevamento di oggetti nei video, e modelli linguistici come Phi-3. La tecnica consente di modificare il loro comportamento in base a determinati trigger, il che la rende universale per un’ampia gamma di sistemi di intelligenza artificiale.
Uno degli aspetti più preoccupanti di tali segnalibri è la loro robustezza e indipendenza da architetture specifiche. Ciò apre la porta agli attacchi contro qualsiasi sistema che utilizzi modelli strutturati a grafico, dalla medicina alla finanza.
I ricercatori avvertono che l’emergere di tali vulnerabilità riduce la fiducia nell’intelligenza artificiale. In un ambiente in cui i modelli sono sempre più integrati nelle infrastrutture critiche, il rischio di bug nascosti può comprometterne l’affidabilità e rallentare lo sviluppo tecnologico.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione Cyber Italia
Cyber Italia