



L’intelligenza artificiale (IA) continua a trovare successo in una vasta gamma di settori, questo trionfo è direttamente collegato alla necessità imperativa di garantirne la sicurezza. L’Adversarial Machine Learning (ML) è un insieme di tecniche che gli avversari utilizzano per attaccare i sistemi di apprendimento automatico. Conoscere questa disciplina è fondamentale per comprendere e valutare i potenziali rischi a cui i sistemi di IA sono sottoposti da azioni avverse di attaccanti malintenzionati.
Questo articolo presenta le più popolari tecniche di Adversarial ML e le loro applicazioni: dagli attacchi al filtro anti-spam di Google agli abbigliamenti stravaganti in gradi di bypassare i sistemi di riconoscimento. Scopri come i ricercatori di Skylight Cyber hanno utilizzato stringhe estratte da video-giochi per eludere l’antivirus Cylance basato su IA!
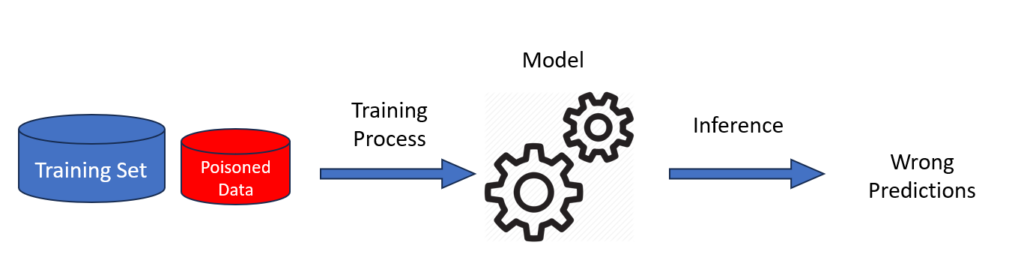
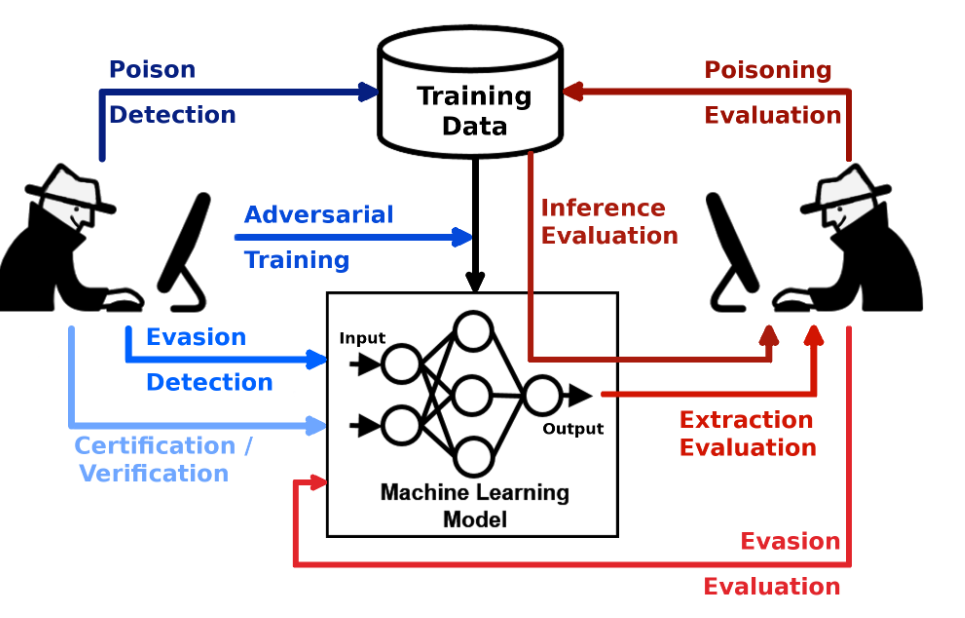
L’Adversarial ML si occupa di attacchi contro i modelli IA. Gli attacchi possono essere di diverso tipo, a seconda degli obiettivi e capacità dell’attaccante. Un tentativo di definizione di una tassonomia riguardo fasi, tecniche e tattiche di un attacco a modelli di IA è fornito dalla matrice Mitre ATLAS, basata sul MITRE ATT&CK framework. Più comunemente, gli attacchi a modelli IA possono essere classificati in tre tipi diversi: il poisoning dei dati, l’evasione del riconoscimento e l’estrazione di dati e modelli. Queste tipologie di offensive agiscono in differenti fasi, di seguito vediamo in dettaglio come funzionano.
Un attacco in cui un avversario mira a influenzare i dati utilizzati nell’addestramento o nel riaddestramento di un modello di IA. Una porzione di dati contaminati vengono immessi nel training-set del modello e fanno sì che esso impari nel modo sbagliato. La contaminazione può consistere nell’associazione di una label sbagliata oppure nella polarizzazione verso una categoria specifica di input.
Google in passato ha rivelato che il filtro antispam di Gmail è stato compromesso almeno quattro volte. Questo tipo di attacco rientra nell’associazione di una label sbagliata, in quanto gruppi operanti nel cyber-crimine hanno deliberatamente segnalato in maniera massiccia e-mail legittime come spam. Tale azione aveva lo scopo preciso di minare l’efficacia del modello di filtraggio, compromettendone l’accuratezza. Attraverso questa tattica, gli aggressori sono stati in grado di inviare varie e-mail dannose, che includevano malware e altre minacce, aggirando efficacemente i filtri di sicurezza senza essere intercettati. Un approfondimento è disponibile qui.
Un altro esempio di data poisoning è il bot Tay di Microsoft: un account Twitter per sperimentare un software IA nel 2016. Tay era programmato per rispondere in modo automatico e naturale a chiunque decidesse di scriverle, in maniera simile all’attuale ChatGPT. Tuttavia, il modello di Tay funzionava in parte per imitazione, ripetendo ciò che gli altri utenti scrivevano. Alcuni account hanno capito il meccanismo e iniziato a postare contenuti razzisti e anti-semiti, portando Tay a ripetere e diffondere tali contenuti.
In generale, questo tipo di tecniche si basano sulla conoscenza dei meccanismi di training o re-training automatico del modello e sulla possibilità di agire, in maniera diretta o indiretta, su fonti dati utilizzati dagli sviluppatori di IA.
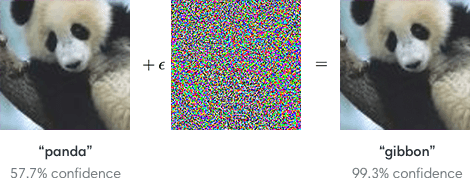
Un attacco di evasione costituisce una strategia attraverso cui un agente malevolo cerca di compromettere le predizioni fatte da un modello di apprendimento automatico. Questo tipo di attacco mira a introdurre piccole e impercettibili modifiche agli input originali al fine di indurre il modello a compiere errori di classificazione. Gli attacchi di evasione sfruttano le vulnerabilità intrinseche dei modelli, cercando di ingannarli attraverso input che, agli occhi umani, sembrano del tutto normali ma che sono stati appositamente elaborati per confondere il modello. Infatti, i modelli di IA, come le reti neurali, sono spesso sensibili a piccole variazioni nei dati di input, come mostrato in figura, in cui una variazione non percettibile dell’immagine stravolge il risultato di un classificatore.
Gli attacchi di questo tipo possono essere differenziati in due categorie: di tipo white box o black box. I primi hanno a disposizione il modello di IA con tutti i suoi parametri, mentre i secondo si basano solo sulle predizioni fatte dal modello. Una delle prime tecniche e le più popolari è FGSM, ecco un tutorial su questo algoritmo.
Un interessante esempio di applicazione di questo tipo di tecniche è legata all’abbigliamento utilizzato per eludere le tecniche di riconoscimento facciale. La start-up cap_able, offre una prima collezione di capi in maglia che proteggono chi li indossa dal software di riconoscimento facciale senza la necessità di coprirsi il volto. Altri tipi di accessori possono essere utilizzati per proteggersi dai più comuni metodi di riconoscimento.
Approcci simili possono essere applicati in altri contesti, come nell’analisi malware. Nel 2019, i ricercatori di Skylight Cyber, hanno affermato di aver aggirato l’antivirus basato su IA di Cylance. In particolare, attraverso delle operazioni di reverse engineering sull’antivirus, i ricercatori sono entrati in possesso del modello e di alcune informazioni legate a meccanismi di white-listing per evitare falsi positivi. I ricercatori hanno scoperto che aggiungere stringhe di popolari video-giochi permette di eludere l’antivirus. Maggiori dettagli sono discussi nel seguente video e nel seguente approfondimento!
In un attacco basato su estrazione, l’obiettivo dell’avversario è recuperare i dati su cui un sistema IA è stato addestrato. Questo tipo di attacco può innescare problemi significativi, soprattutto quando sia i dati di addestramento che il modello stesso sono di natura sensibile e riservata. In situazioni estreme, l’estrazione dei dati può persino sfociare nel cosiddetto “model stealing“, un processo in cui vengono estratti dati in quantità sufficiente dal modello per permettere la ricostruzione completa di quest’ultimo. Questo scenario rappresenta una grave minaccia in quanto l’avversario potrebbe acquisire conoscenze fondamentali riguardo all’architettura e alle caratteristiche del modello, consentendo loro di replicarlo o utilizzarlo per scopi non autorizzati.
Un esempio per questo tipo di attacchi è la CVE-2019-20364, legata ai servizi anti-spam di Proofpoint. In particolare, raccogliendo i punteggi dalle intestazioni delle e-mail di Proofpoint, è possibile ricreare un modello di classificazione ed estrarre approfondimenti da questo modello. Le informazioni raccolte consentono a un utente malintenzionato di creare e-mail che ricevono punteggi a piacere, con l’obiettivo di recapitare e-mail dannose.
La mitigazione dei rischi associati all’adversarial machine learning richiede una serie di strategie e tecniche mirate per proteggere i modelli dagli attacchi avversari. Ecco alcuni approcci:
L’implementazione di una combinazione di queste tecniche e strategie può aiutare a mitigare i rischi associati all’adversarial machine learning e a garantire che i modelli di machine learning siano più resistenti agli attacchi avversari. Per questi scopi, adversarial-robustness-toolbox è un tool che consente di effettuare analisi di robustezza ed assessment di vulnerabilità su modelli di ML, come mostrato in figura.
L’Adversarial ML rappresenta una sfida cruciale per la sicurezza dell’IA. La consapevolezza delle varie tipologie di attacco e l’implementazione di difese adeguate possono contribuire a garantire che i benefici dell’IA siano sfruttati in modo sicuro e responsabile, proteggendo la privacy, la proprietà intellettuale e la fiducia nell’utilizzo dei sistemi di apprendimento automatico. Più i modelli di IA verranno utilizzati in prodotti di uso comune, più sarà necessario indagare e stabilire procedure per garantire la sicurezza di tali applicazioni.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione