



Benvenuti alla seconda parte della nostra serie di articoli sulle reti neurali ricorrenti (RNN). Nel nostro precedente articolo, abbiamo fornito una panoramica generale delle RNN, esaminando il loro ruolo nell’ambito dell’intelligenza artificiale e del machine learning. In questo articolo, ci immergeremo più profondamente nell’architettura e nel funzionamento delle RNN, esplorando la loro unicità e la loro potenza nel trattamento dei dati sequenziali.
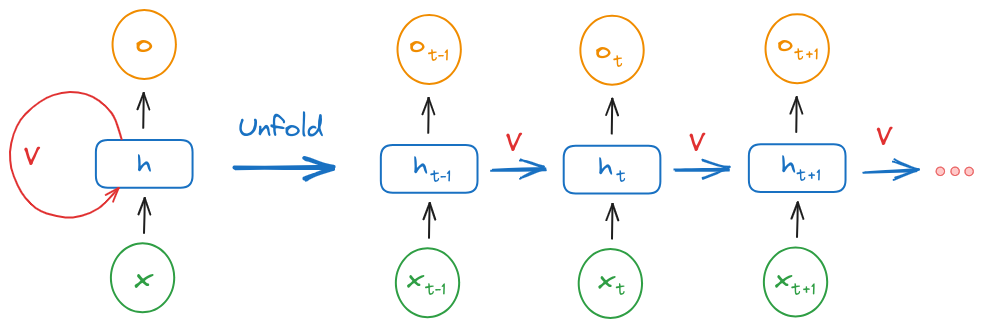
Le RNN, come suggerisce il loro nome, sono caratterizzate da connessioni “ricorrenti”. Questo significa che hanno cicli nei loro percorsi di calcolo, a differenza delle reti neurali feedforward (FNN), in cui le informazioni fluiscono solo in una direzione, dall’input all’output.
L’architettura di una RNN è costituita da uno strato di input, uno o più strati nascosti e uno strato di output. Ogni strato è composto da un insieme di neuroni artificiali o nodi. La caratteristica distintiva delle RNN è che i nodi nello strato nascosto hanno una connessione “ricorrente”, ovvero una connessione che forma un ciclo, permettendo alle informazioni di circolare all’interno dello strato.
Questa struttura permette a una RNN di conservare un “stato nascosto” che mantiene l’informazione sulla sequenza dei dati fino a quel momento. Questo stato nascosto agisce come una sorta di memoria, permettendo alla rete di ricordare l’informazione passata e di usarla per fare previsioni sul futuro.
Per capire come questo funziona in pratica, potrebbe essere utile un esempio. Immaginiamo una RNN progettata per tradurre una frase dall’inglese all’italiano. Quando la rete elabora la frase “I love reading”, deve essere in grado di ricordare la relazione tra “I” e “love”, e tra “love” e “reading”, per tradurre correttamente la frase in “Io amo leggere”. Questo è possibile grazie allo stato nascosto, che conserva le informazioni sui termini precedenti nella sequenza.
Per comprendere il funzionamento interno di una RNN, è utile immaginare la rete “spiegata” (unfold) nel tempo. Questa è una tecnica comune utilizzata per visualizzare l’elaborazione sequenziale in una RNN. In questa rappresentazione, ogni passo temporale della sequenza viene mostrato come un nodo separato nella rete.
Quando una RNN processa una sequenza di dati, inizia dall’inizio della sequenza e aggiorna il suo stato nascosto ad ogni passo temporale. Questo aggiornamento dello stato nascosto è calcolato in base al dato corrente e allo stato nascosto precedente.
In termini matematici, lo stato nascosto a un certo passo temporale t (denotato come hT) viene calcolato come segue:
hT = f(Whh * h(t-1) + Whx * xt)
In questa formula, Whh e Whx sono matrici di pesi che la rete apprende durante il training, xt è il dato di input al passo temporale t, e f è una funzione di attivazione non lineare, come la tangente iperbolica (tanh) o la funzione ReLU (Rectified Linear Unit).
Una volta calcolato il nuovo stato nascosto ht, la RNN produce un output per il passo temporale corrente. Questo output è in genere calcolato utilizzando una funzione di attivazione softmax, che produce un vettore di probabilità per le possibili previsioni.
Il processo descritto viene ripetuto per ogni passo temporale della sequenza. Alla fine della sequenza, la RNN avrà prodotto una serie di output, uno per ogni passo temporale.
Mentre l’architettura base delle RNN è potente, esistono diverse varianti che cercano di superare alcuni dei suoi limiti. Due delle varianti più note sono le Long Short-Term Memory (LSTM) e le Gated Recurrent Unit (GRU), che introducono nuovi meccanismi per controllare come le informazioni vengono passate attraverso la rete. Queste varianti saranno oggetto di discussione più approfondita nel nostro quarto articolo.
In questo articolo, abbiamo esplorato l’architettura e il funzionamento delle RNN. Questi concetti fondamentali ci aiutano a capire come le RNN siano in grado di gestire dati sequenziali in modo così efficace, rendendole strumenti potenti per l’elaborazione del linguaggio naturale, la previsione delle serie temporali e molto altro ancora.
Tuttavia, come vedremo nel prossimo articolo, le RNN non sono senza sfide. Il problema della “scomparsa del gradiente” è una questione critica che può rendere difficile l’addestramento delle RNN su lunghe sequenze. Inoltre, esistono diverse varianti dell’architettura RNN, come le LSTM e le GRU, che cercano di superare alcuni dei limiti delle RNN standard. Esploreremo queste sfide e le possibili soluzioni nel nostro prossimo articolo.
Per coloro che sono interessati a esplorare ulteriormente l’architettura e il funzionamento delle RNN, consigliamo le seguenti risorse:
Recurrent Neural Networks by Example in Python: Un tutorial pratico che mostra come costruire una RNN in Python.
The Unreasonable Effectiveness of Recurrent Neural Networks: Un post del blog di Andrej Karpathy che esplora l’efficacia delle RNN attraverso vari esperimenti.
Deep Learning Book – Chapter 10: Un capitolo del libro “Deep Learning” di Ian Goodfellow, Yoshua Bengio e Aaron Courville, che offre un approfondimento tecnico sulle RNN e le loro varianti.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione