



Nell’ultimo articolo, abbiamo introdotto le Convolutional Neural Networks (CNN), un’innovazione cruciale nel campo dell’intelligenza artificiale che ha rivoluzionato il riconoscimento di immagini e suoni. Adesso, è tempo di esaminare più da vicino come queste affascinanti reti lavorano dietro le quinte, le black box non ci sono mai piaciute!
Questo articolo esplora l’architettura delle CNN, il flusso dei dati attraverso la rete e il processo di estrazione e interpretazione delle caratteristiche rilevanti dai dati in ingresso.
Per i prossimi paragrafi utilizzeremo l’architettura di seguito come esempio:
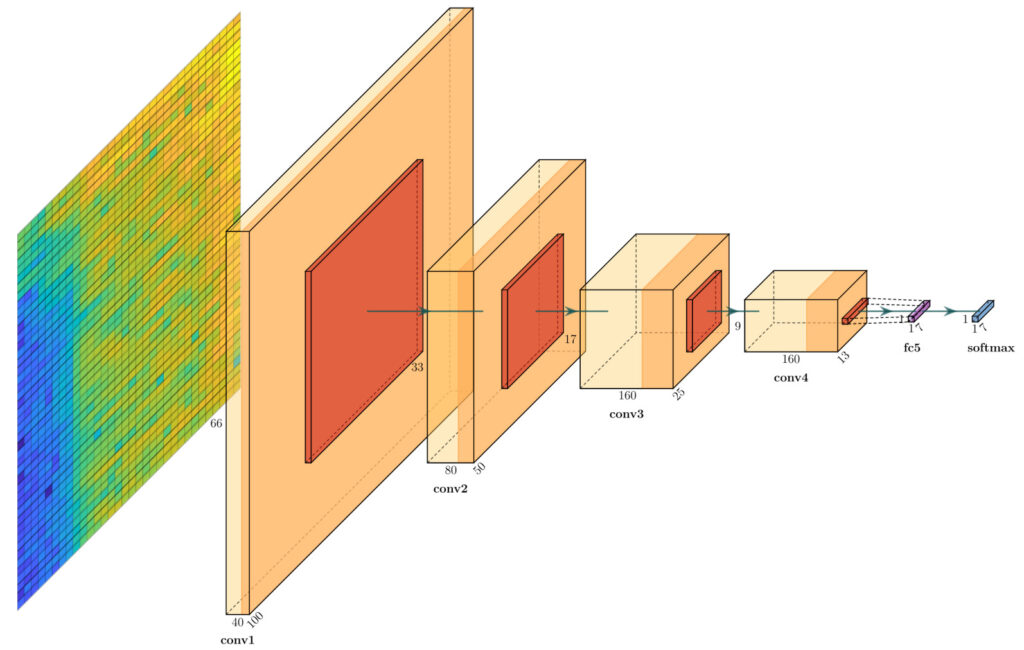
Ho sviluppato questa architettura durante il mio dottorato di ricerca per il progetto Sound of Guns: Digital Forensics of Gun Audio Samples meets Artificial Intelligence. In tale progetto, la CNN in questione è stata utilizzata per classificare tipo, modello e calibro di armi da fuoco a partire dallo spettrogramma della registrazione del colpo.
Le CNN prendono il nome da una delle loro caratteristiche fondamentali: lo strato convoluzionale. Questo strato è il nucleo dell’apprendimento della rete, il luogo in cui le caratteristiche (o “pattern”) dei dati vengono effettivamente riconosciute.
In uno strato convoluzionale (in giallo, nella figura di riferimento), l’immagine di input viene suddivisa in diverse regioni sovrapposte. Ciascuna di queste regioni viene poi trasformata da una serie di “filtri” o “kernel”, matrici di numeri che alterano i dati dell’immagine. Ogni filtro è progettato per rilevare una caratteristica specifica nell’immagine, come un bordo, una linea o un angolo. L’output di questo processo è una serie di “mappe delle caratteristiche”, rappresentazioni dell’immagine originale che evidenziano le aree in cui è stata rilevata una particolare caratteristica.
Dopo che le immagini sono state filtrate attraverso lo strato convoluzionale, arrivano allo strato di pooling (in arancio, nella figura di riferimento). Lo scopo di questo strato è ridurre la dimensione delle mappe delle caratteristiche senza perdere le informazioni importanti. Questo processo di “sottocampionamento” rende l’intera rete più efficiente, riducendo il numero di parametri da calcolare.
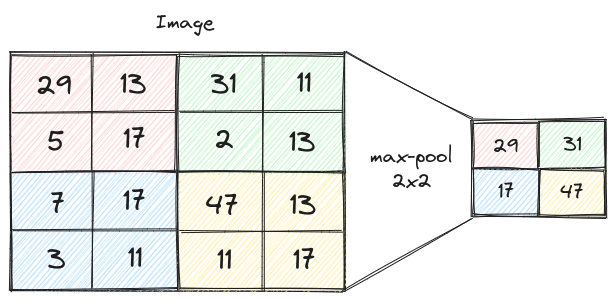
Esistono diversi metodi di pooling, ma il più comune è il “max pooling”, che prende il valore massimo da una regione della mappa delle caratteristiche. Questo significa che, indipendentemente da dove una caratteristica viene rilevata all’interno di una certa regione, essa sarà preservata nello strato di pooling.
Dopo che i dati sono stati processati attraverso gli strati convoluzionali e di pooling, entrano negli strati “fully connected” o “densi” (in viola, nella figura di riferimento). Come suggerisce il nome, in questi strati ogni neurone è connesso a ogni altro neurone nello strato precedente e nel successivo.
Qui, le mappe delle caratteristiche vengono “appiattite” in un vettore unidimensionale che può essere alimentato attraverso la rete neurale. Lo scopo di questi strati è interpretare le caratteristiche rilevate nelle fasi precedenti e combinare queste informazioni in una previsione finale. Ad esempio, in un problema di riconoscimento di immagini, questo potrebbe significare decidere se l’immagine rappresenta un gatto o un cane.
L’ultimo strato di una CNN è lo strato di output (in blu, nella figura di riferimento). Questo strato è responsabile della produzione della previsione finale della rete. In un problema di classificazione, ogni neurone in questo strato rappresenta una possibile etichetta che la rete può prevedere, e la funzione di attivazione viene utilizzata per convertire l’output della rete in una distribuzione di probabilità tra queste etichette.
Le funzioni di attivazione più comuni negli strati di output delle CNN sono la funzione softmax per la classificazione multiclasse e la funzione sigmoide per la classificazione binaria. Entrambe queste funzioni comprimono l’output della rete in un intervallo che è utile per l’interpretazione delle previsioni.
Le Convolutional Neural Networks sono uno strumento potente nel riconoscimento di immagini e suoni, grazie alla loro capacità di apprendere gerarchie di caratteristiche spaziali. A partire dal riconoscimento di caratteristiche locali o globali nello strato convoluzionale, passando per la riduzione della dimensionalità nello strato di pooling, fino all’interpretazione delle caratteristiche negli strati fully connected, ogni elemento dell’architettura CNN svolge un ruolo chiave nel processo di apprendimento.
Nel nostro prossimo articolo, esploreremo come le CNN vengono addestrate e ottimizzate, gettando luce sul processo di backpropagation e discutendo le tecniche comuni per l’ottimizzazione delle reti neurali.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione