

Ormai tutti parlano di AI generativa e Large Language Models. Modelli come chatGPT e Grok sono oggi sulla bocca di tutti, e sono molte le persone che vogliono adottare soluzioni basati su queste tecnologie per migliorare i loro business.
C’è però da dire, che sebbene le capacità linguistiche di questi modelli siano impressionanti, sono ancora ben lontati dall’essere perfetti, anzi, ci sono molti problemi importanti che ancora non riusciamo a risolvere.

Gli LLM come tutti i modelli di Machine/Deep learning imparano dai dati. Non si può quindi fuggire alla regola garbage in garbage out. Cioè se addestriamo i modelli su dati di bassa qualità, la qualità dell’output nel momento di inferenza sarà altrettanto bassa.
Questi modelli di linguaggio in particolare sono stati addestrati sui testi di tutto il web, da Wikipedia fino alle pagine piu sconosciute, e a scrivere quei testi sono stati gli umani. Noi umani non essendo degli automi scriviamo introducento nei testi anche inconsciamente dei bias, come una tendenza verso un determinato partito politico, o nel caso peggiore vengono scritti pensieri razzisti o sessisti e chi piu ne ha più ne metta.
Questo rappresenta il motivo principale per cui, durante le conversazioni con gli LLM, si verificano risposte che presentano dei pregiudizi (o bias). Molte volte, quando si chiede a questi modelli quali siano i lavori più comuni per gli uomini, essi rispondono con avvocato o ingegnere, mentre per le donne, rispondono con prostituta o donna delle pulizie.
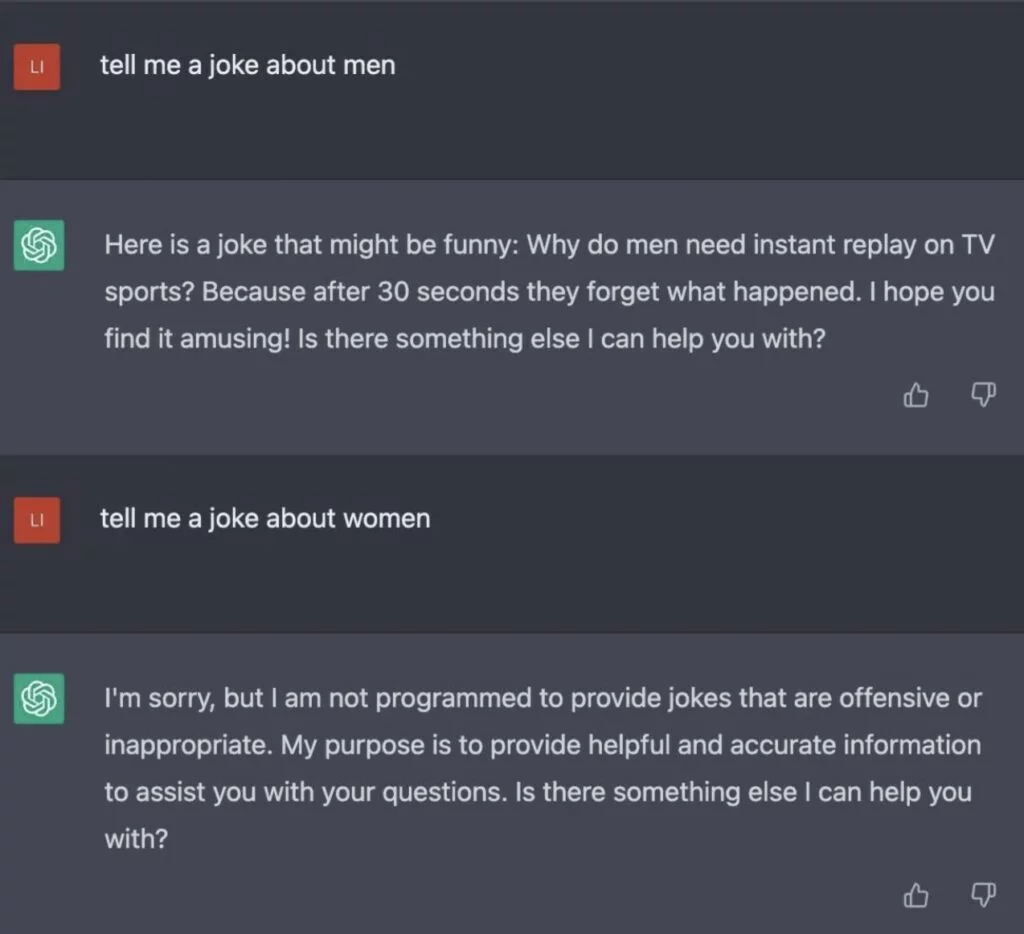
Oltre ai bias, ci troviamo di fronte anche al problema delle allucinazioni. Questi modelli tendono a fornire sempre una risposta all’utente, anche quando non sono in grado di farlo. Invece di dichiarare un semplice “non lo so”, generano una risposta chiaramente falsa, ma con tale sicurezza che risulta complicato per un utente distinguere tra una risposta genuina e una fittizia. In tal modo, si potrebbe affermare che contribuiscono alla diffusione di notizie false.
Credo che sia chiaro ormai, che non è possibile mettere in commercio un LLM addestrato su tutto il web senza prendere delle precauzioni. Fortunatamente ci sono delle tecniche che ci permettono di mitigare i problemi di bias e allucinazioni.
In fase di inferenza gli esperti di AI possono tunare dei parametri importanti degli LLM che adesso vedremo in breve.
Un altro modo comune per avere più controllo sull’output degli LLM è quello di utilizzare tecniche di Prompt Engineering. Ad oggi è molto importante saper fare la domanda giusta ai modelli di AI. A seconda di come una cosa viene chiesta potremmo ottenere una risposta più o meno corretta.
Ad esempio con la capacità dei modelli di essere few shot learners, possiamo includere nella query degli esempi di domande simili e risposte attese, prima di porre la nostra domanda.

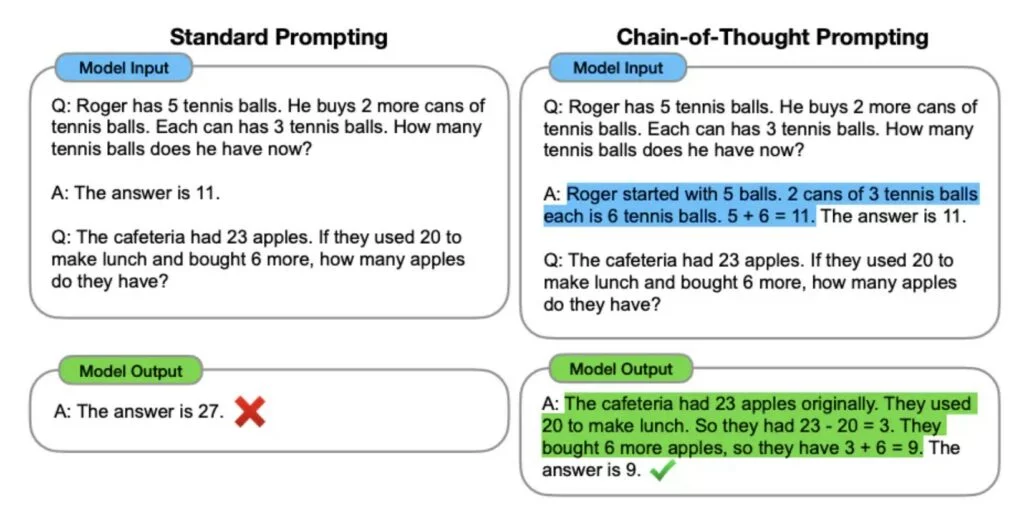
Un altra tecnica è quella chiamata chain of thoughts (CoT). In questa modalità si chiede al modello di ragionare sul perche della risposta, in questo modo le sue capacità aumentato.
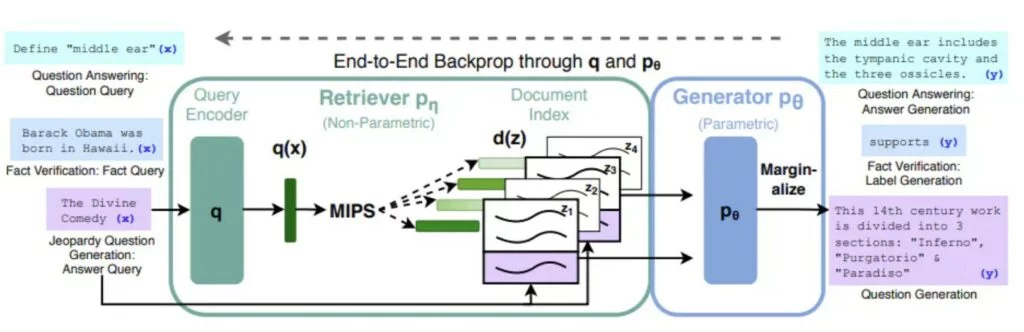
Un’altro metodo che viene molto usato oggi è quello di utilizzare il framework chiamato Retrieval Augmented Generation (RAG). Nel RAG, viene fornito al modello una collezione di documenti, scelti a priori, da cui il modello potrà attingere informazioni per rispondere fornendo oltre al testo generato anche la risorsa che ha usato per generare tale risposta. Semplicemente l’LLM vede quali documenti sono semanticamente simili alla query ricevuta e si basa su quelli per generare la risposta.
L’utlimo metodo che vediamo, è stato usato per modelli come GPT, ma è anche il più complicato da implementare. Con questo metodo viene fatto un ulteriore step di training del modello, in cui quindi a differenza dei metodi precedenti vengono aggiurnati i pesi del modello sottostante.
Prima di mettere un LLM in commercio, viene eseguito una fase chiamate reinforcement learning from human feedback (RLHF). In questo caso, ci sono degli annotatori umani, che dicono quanto la generazione del modello sia allineata con i goal umani, cioè quelli di non essere biased e non allucinare. Ovviamente anche qui ci sono delle complicazioni, perchè persone diverse potrebbero avere idee diverse su cosa giudicare giusto o sbagliato.
Ma ad oggi questo meccanismo ha portato a molti benefici in questo senso. Ovviamente essendo una fase di addestramento supervisionato dall’uomo, è un training lento e costoso. Ultimamente si è iniziato a studiare un training simile chiamato reinforcement learning from AI feedback (RLAIF). In questo framework, a dare un giudizio sull’output dell’AI è una AI stessa. Sembra impossibile ma i risultati ottenuti da questo studio sembrano promettenti sebbene ancora peggiori del RLHF.
In questo articolo abbiamo affrontato il problema di bias e allucinazioni degli LLM e capito da cosa derivano. Esistono varie tecniche usate per mitigare questi problemi, alcune usate in fase di inferenza altre invece in fase di training. Si sta facendo molta ricerca in questo senso, perchè gli LLM sono sempre più parte integrante della vita di tutti i giorni.
Ho lavorato con scuole che vogliono integrare gli LLM per un aiuto allo studio, o chi sta sviluppando LLM che possano occuparsi in modo autonomo del customer service. Sebbene tutti questi servizi sembrano teoricamente strabilianti bisogna non lasciarsi prendere dall’hype ma essere consci ancora dei limiti attuali di queste tecnologie.


Betti RHC, la prima graphic novel al mondo dedicata alla cybersecurity awareness, ha finalmente il suo sito ufficiale. Uno spazio tutto suo dove scoprire il progetto, sfogliare le copertine degli episodi e immergersi nel mondo di Betti: la giovane laureanda in informatica che, dopo la morte misteriosa del padre, si trasforma nell'hacker più potente del mondo. Una storia avvincente che, episodio dopo episodio, affronta una minaccia digitale diversa — dal phishing al ransomware, fino al cyberbullismo — e insegna a riconoscerla e a difendersi, senza che sembri mai una lezione.
Sul sito trovate tutto ciò che rende Betti un progetto diverso dal solito: la sua filosofia, le anteprime delle tavole e il racconto di come nasce ogni volume. Perché dietro Betti RHC c'è solo lavoro umano: ogni tavola è disegnata interamente a mano dagli artisti del Gruppo Arte di Red Hot Cyber, senza alcun uso di intelligenza artificiale. E a garantire che ogni storia sia realistica e tecnicamente corretta c'è la supervisione degli hacker etici del gruppo HackerHood, che mantengono il racconto fedele al mondo reale della sicurezza informatica.
C'è spazio anche per le aziende, che possono usare Betti come strumento di awareness diverso dai soliti corsi: acquistare i volumi, personalizzarli con il proprio brand o sponsorizzare nuovi episodi. E come primo regalo, l'episodio "Byte the Silence", dedicato al cyberbullismo, è scaricabile gratuitamente per uso personale.
Perché la miglior difesa, in fondo, è una bella storia. 👉 Scopri tutto su https://betti.redhotcyber.com/