



Tradizionalmente, l’AI inference è stato il dominio di data center centralizzati e cluster di calcolo ad alte prestazioni, accessibili solo a pochi. Questo è ancora il caso per molte decentralized inference networks, dove gli operatori dei nodi devono affidarsi a hardware di fascia alta per poter guadagnare ricompense che, di fatto, servono solo a mitigare le loro spese.
Questo non democratizza l’accesso all’AI: la maggior parte degli utenti non è in grado di partecipare attivamente alla fase di inference a causa degli elevati costi delle GPU, e i clienti che desiderano un decente livello di decentralizzazione o privacy si ritrovano con soluzioni davvero lente o costose.
Negli ultimi mesi, il team di BrianknowsAI ha lavorato su qualcosa che potrà essere una svolta nell’intersezione tra AI e web3: il DCI Network. Ma prima di parlarne, facciamo un passo indietro e vediamo perché ci siamo trovati in questa situazione in primo luogo.
Le Neural Networks sono, come suggerisce il nome, reti di neuroni artificiali organizzati in strati. Tutti i neuroni in uno strato eseguono la stessa operazione sui dati di input forniti, spesso definiti come operators. Gli strati all’interno di una Neural Network sono connessi tramite bordi pesati; regolare questi pesi durante il training è ciò che fa “imparare” una Neural Network. Questi pesi sono spesso chiamati parameters.
Oggi le Neural Networks crescono costantemente in complessità, e quando la loro complessità aumenta, crescono anche i requisiti computazionali e l’memory footprint per eseguire sia l’inference che il training.
Modelli complessi hanno più strati, più neuroni e architetture più grandi, il che contribuisce a un enorme numero di operazioni matematiche che devono essere calcolate. Quando un dispositivo esegue questi calcoli, deve memorizzare il risultato in memoria.
Una Neural Network è “grande” quando si verifica una (o più) delle seguenti condizioni:
Durante la fase di inference di una Deep Neural Network (DNN), i dati di input vengono elaborati attraverso ogni strato della rete per produrre un output. Due fattori critici influenzano questa fase: l’memory footprint (la quantità di memoria necessaria per contenere la rete e i dati) e i GOP (Giga [10⁹] Operations) richiesti per generare il risultato. Se un dispositivo non ha memoria sufficiente per ospitare l’intera rete, non può eseguire l’inference. Anche se la memoria è adeguata, una potenza di calcolo limitata può causare ritardi significativi nell’elaborazione, rendendo l’inference impraticabilmente lenta su dispositivi meno potenti.
Il problema che vogliamo risolvere è: “Come possiamo eseguire l’inference di un modello grande su un dispositivo limitato dall’hardware?”. O, in altre parole, come possiamo usare un modello grande su un dispositivo che non è in grado di gestire gli operators e i parameters del modello?
Immaginiamo il concetto “astratto” di DNN come il concetto di Graph, dove i dati sono rappresentati da tensors e calcolati da operators. Un tensor è un vettore n-dimensionale di dati (o tensore) che scorre attraverso il graph (o NN); ci sono due tipi di tensors: input tensors (X) e output tensors (Y). Un esempio di input tensors sono i parameter tensors (che servono come input statico per gli operators). Quando un tensor è il risultato dell’output di un operator, viene chiamato activation tensor.
Eseguire l’inference su un modello significa calcolare tutte le attivazioni degli operators usando un input tensor (il nostro prompt nel caso di un LLM) e ottenere l’output tensor (il nostro risultato — un’immagine, un testo, ecc.).
La tendenza attuale nello sviluppo dei large language models (LLMs) si concentra sullo scaling up, ossia sull’espansione delle dimensioni dei modelli e sul miglioramento delle capacità hardware. Sebbene questo approccio ottenga prestazioni all’avanguardia, introduce sfide significative quando si tratta di distribuire o interagire con tali modelli:
Diverse strategie vengono sfruttate per mitigare queste sfide, specialmente per ridurre i requisiti computazionali degli LLMs. Queste tecniche funzionano semplificando i modelli senza degradarne gravemente le prestazioni:
Per ulteriori informazioni su queste soluzioni, puoi consultare il mio articolo precedente:
Efficient Deep Learning: Unleashing the Power of Model Compression
Accelerare la velocità di inference del modello in produzione
towardsdatascience.com
Questi metodi possono aiutare ma non si adattano completamente ai modelli grandi, e in tutti i casi c’è un compromesso sulle prestazioni. Invece di affidarsi a un singolo dispositivo, prendiamo in considerazione la distribuzione del calcolo su più dispositivi. Formando una rete di dispositivi, ciascuno contribuendo al calcolo complessivo, i modelli più grandi possono essere eseguiti in modo più efficiente. Questo permette anche:
Il Decentralized Collaborative Intelligence Network, o DCI Network, è una rete di nodi che condividono potenza computazionale per eseguire inference su modelli open source.
Per “collaborative intelligence” intendiamo un sistema distribuito in cui più attori contribuiscono a risolvere un problema specifico calcolando autonomamente una parte della soluzione di tale problema. Nel contesto del DCI Network, gli attori sono i nodi, il problema è l’inference di un modello e la soluzione è il risultato dell’inference.
L’approccio che vogliamo usare è dividere il neural network graph in subgraphs e assegnare ogni subgraph a un dispositivo specifico. Eseguendo l’inference su questi subgraphs, riduciamo drasticamente i requisiti computazionali su ogni dispositivo.
Il processo di divisione del graph in subgraphs è noto come Layer Sharding. Gli strati e/o sottostrati possono essere allocati ai dispositivi del DCI Network in diversi modi basati su una varietà di strategie.
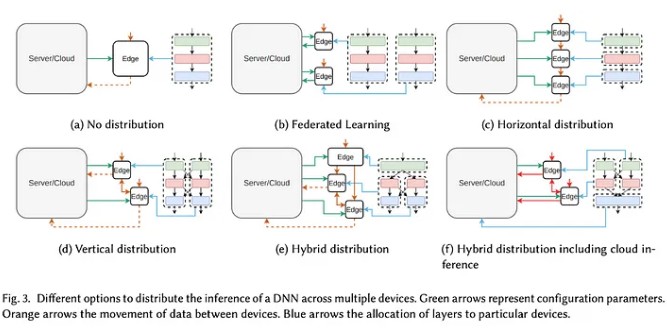
Quando si implementa il Layer Sharding in modo orizzontale (sequenziale), all’interno di una rete di dispositivi con diverse potenze computazionali, ci sono due sfide principali da affrontare (ne parleremo più avanti):
Sviluppare una rete del genere pone molteplici sfide:
In un sistema runtime statico, l’algoritmo di distribuzione viene eseguito solo una volta durante la fase di compilazione di un DNN. Dopo questo, la rete viene partizionata e assegnata a diversi dispositivi, che vengono poi utilizzati per le operazioni effettive. Poiché la distribuzione è determinata al momento della compilazione, si possono impiegare algoritmi più complessi per un’allocazione ottimale dei compiti, non essendo vincolati da prestazioni in tempo reale. Questo permette un’analisi approfondita e un’esecuzione algoritmica più lunga senza influire sulle prestazioni runtime del sistema.
In un sistema runtime adattivo, la topologia della rete cambia dinamicamente per ottimizzare alcune metriche. La variabile più comune monitorata è di solito la banda tra i dispositivi della rete. In questo modo, è possibile modificare le allocazioni dei dispositivi per ottimizzare latenza e bilanciamento del carico.
La ricerca relativa al calcolo distribuito si è concentrata principalmente sull’ottimizzazione di tre aspetti di tali reti:
La maggior parte degli studi si concentra sull’ottimizzazione di un solo tipo di metrica, e il nostro obiettivo primario è ottimizzare la metrica della latency. Tuttavia, crediamo che generare problemi di ottimizzazione multi-obiettivo si presenti come una direzione di ricerca e sviluppo promettente.
Vedremo nei prossimi paragrafi come intendiamo affrontare queste sfide.
I nodi del DCI Network svolgono due scopi principali all’interno della rete:
Il DCI Network è una rete P2P. La topologia della rete è costruita tramite un graph; ogni nodo del graph contiene il suo ID e la descrizione del dispositivo stesso (memoria, chip, ecc.). La scoperta dei peer avviene attraverso questo graph.
Un nodo, per entrare a far parte di questa rete, deve possedere la private key o la seed phrase di un wallet che ha messo in staking una quantità fissa di token.
Nel DCI Network, qualsiasi dispositivo può partecipare: che si tratti di un MacBook Pro, un laptop Linux o un dispositivo mobile (come un telefono iOS). Questo è possibile grazie al già citato distributed model parallelism.
Abbiamo già descritto come possiamo considerare una Neural Network come un graph e come il DCI Network sia strutturato esso stesso come un graph. Per semplificare la comprensione dei passaggi successivi:
Abbiamo anche discusso come creare subgraphs del model graph iniziale ci permetta di distribuirli su più dispositivi per risolvere il problema legato ai requisiti hardware.
Il nostro obiettivo ora è trovare la migliore partitioning strategy per assegnare gli strati a ogni dispositivo nel modo più efficace.
Con partitioning strategy intendiamo un algoritmo che divide in modo ottimale gli strati del modello e li assegna a un nodo della rete per essere calcolati. Descriviamo la Ring Memory-Weighted Partitioning Strategy (proposta da Exo Labs) e poi proponiamo la nostra soluzione più avanzata.
In una rete a forma di anello, ogni nodo riceverà l’input per il suo chunk di modello locale dal nodo precedente nella catena di comunicazione, e lo elaborerà per trasmettere il suo output al nodo successivo. A causa della natura autoregressiva degli LLMs, le informazioni di output dovranno essere reinserite nell’input per generare un altro token. Ecco perché le strategie di partizionamento proposte sono le più adatte al nostro caso d’uso.
In questa strategia, la rete funziona dividendo il flusso di lavoro usando un partizionamento pesato tra tutti i nodi che partecipano alla rete. Ogni dispositivo contribuisce all’inference in base alla seguente formula:
n = device_memory / total_memory
dove n è il numero di partizioni del modello, device_memory è la memoria disponibile del dispositivo per l’inference e total_memory è la quantità totale di memoria della rete. La memoria totale della rete viene calcolata tramite la trasmissione delle risorse disponibili dagli altri nodi.
In altre parole, ogni dispositivo contribuisce proporzionalmente a quante risorse condivide con la rete rispetto a quanto è grande la rete, ed è ricompensato in base a tale proporzione.
Usando una Ring Memory-Weighted Partitioning Strategy (come quella illustrata nell’immagine proposta da Exo Labs nella loro implementazione exo), i nodi sono ordinati per la loro memoria totale in ordine crescente, e in base al loro valore n (calcolato nella formula sopra) vengono determinati uno strato iniziale e uno finale del modello. Questi saranno gli strati iniziale e finale del modello che quel particolare nodo utilizzerà per l’inference.
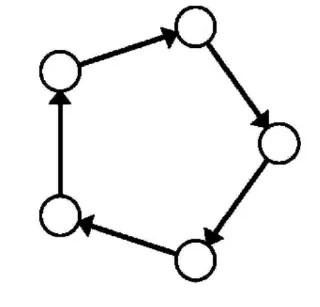
Proponiamo un’evoluzione della Ring Memory-Weighted Partitioning Strategy: la chiamiamo Layer-Aware Ring Memory-Weighted Partitioning Strategy (o Layer-Aware RMW).
La Ring Memory-Weighted Partitioning Strategy è una strategia statica: ciò significa che il partizionamento prende in considerazione solo le risorse della rete e viene aggiornato solo quando un nodo si unisce o lascia la rete.
La nostra soluzione, invece, è dinamica perché cambia ogni volta in base al modello richiesto: questo perché il partizionamento non si basa solo sulle risorse della rete, ma calcoliamo anche le necessità computazionali di ogni strato del modello e assegniamo gli strati più intensivi dal punto di vista computazionale ai dispositivi con le migliori prestazioni nella rete.
Per far funzionare questo, dobbiamo eseguire:
Dato un insieme di strati (con le loro complessità computazionali e requisiti di memoria associati) e un insieme di dispositivi (la nostra rete) con le loro potenze di elaborazione, dobbiamo risolvere un problema di ottimizzazione in cui l’obiettivo è bilanciare il carico computazionale e l’uso della memoria tra tutti i dispositivi.
Risolvere questo problema significa:
Essendo il DCI Network una rete decentralizzata, dobbiamo fornire validation (o verifica) per garantire che i nodi stiano effettivamente eseguendo l’inference sugli strati corretti e restituendo l’output corretto al nodo successivo/all’utente.
Abbiamo quindi introdotto il concetto di staking per permettere ai nodi di entrare nella rete.
Lo staking è una strategia usata nel mondo delle criptovalute e del web3 che consente agli utenti di partecipare a mantenere una rete blockchain onesta e sicura.
Ora dobbiamo vedere come e perché dovremmo eseguire lo slashing su tali stakeholder in caso agiscano in modo malevolo. Quando si parla di inference verificabile, ci sono due tipi di approcci che potremmo adottare: proof-based e cryptoeconomics-based.
Le proof-based validations, come suggerisce il nome, sono approcci che usano prove per verificare che l’inference sia stata eseguita correttamente. Per l’ambito del DCI Network, prenderemo in considerazione solo due tipi di proof-based validation: Zero-Knowledge Proofs e Optimistic Fraud Proofs. I seguenti tre paragrafi sono un estratto dell’eccellente lavoro svolto in questo paper.
zkML (Zero-Knowledge Machine Learning) rappresenta un nuovo paradigma all’intersezione tra ML e Blockchain: sfruttando zk-SNARKS (Zero-Knowledge Succinct Non-Interactive Arguments of Knowledge), protegge la riservatezza nei parameters del modello e nei dati degli utenti sia durante il training che nei processi di inference. Questo può mitigare le preoccupazioni sulla privacy ma anche ridurre il carico computazionale sulla rete blockchain.
Ciò che è più affascinante di zkML è il fatto che è in grado di generare prove di dimensione fissa, indipendentemente da quanto grande sia il modello. Questo approccio crittografico, inoltre, garantisce sempre la correttezza.
D’altra parte, il costo di compilare un DNN in un circuito zero-knowledge si è dimostrato estremamente difficile e anche estremamente costoso: alcuni studi hanno mostrato un aumento di 1000 volte del costo dell’inference e della latenza (a causa della generazione della prova). Anche se questo costo può essere distribuito tra i nodi o trasferito all’utente, rimane comunque molto elevato.
opML (Optimistic Machine Learning) porta invece un nuovo paradigma: fidati, ma verifica. Questo approccio presume sempre che l’inference sia corretta, e dopo che è stata generata, i nodi validatori possono segnalare un nodo per aver generato un’inference errata usando una fraud proof.
Se un nodo validatore genera un’inference diversa, può avviare una disputa che può essere risolta on-chain.
Ciò che è davvero forte di opML è il fatto che, finché c’è un singolo validatore onesto nella rete, non c’è incentivo per i nodi di inference effettivi ad agire in modo malevolo, poiché perderanno la disputa e subiranno lo slashing. È anche molto meno costoso di zkML, ma il costo scala proporzionalmente al numero di nodi validatori presenti. Nel contesto del DCI Network, il costo scala anche con il numero di nodi di inference disponibili, poiché tutti i nodi validatori devono rieseguire le inference calcolate. Un altro problema con opML riguarda la finality: dobbiamo aspettare il periodo di sfida per accettare un’inference come corretta o meno.
Questi due approcci differiscono davvero l’uno dall’altro. Vediamo le loro principali differenze, pro e contro:
Questi approcci saltano i dettagli crittografici e matematici complessi, concentrandosi esclusivamente sul raggiungimento del risultato desiderato.
Un esempio molto semplice di tale approccio nel contesto del DCI Network è lasciare che l’inference venga eseguita da più nodi (N) contemporaneamente; i risultati vengono confrontati tra loro e la maggior parte dei nodi con la stessa risposta sono considerati “corretti” e vengono passati ulteriormente nell’anello; quelli diversi vengono respinti e subiscono lo slashing.
Con questo approccio, la latenza dipende dal numero di nodi e dalla complessità dell’inference, ma poiché l’obiettivo del DCI Network è ridurre la complessità della rete, possiamo dire ottimisticamente che tale approccio ha una latenza veloce.
Tuttavia, la sicurezza è al suo punto più debole, poiché non possiamo sfruttare la crittografia o la matematica per garantire che l’output sia corretto: se un numero ragionevole di nodi deviasse (razionalmente o irrazionalmente), potrebbe influire sul risultato dell’inference.
Ciò che è davvero interessante, però, è che questo “problema di sicurezza” è vero per la maggior parte delle “decentralized inference networks” là fuori che eseguono semplicemente inference ridondanti e usano uno schema commit-reveal. Nel DCI Network, invece, possiamo sfruttare diverse tecniche per mitigare tali problemi di sicurezza: la prima è utilizzare EigenLayer restaking e attributable security per consentire alla rete di fornire una “assicurazione” in caso di fallimento della sicurezza.
La seconda merita un paragrafo a sé.
A causa della natura del DCI Network, l’inference viene calcolata passo dopo passo su un batch di strati invece che sull’intero modello. Come già menzionato in questo documento, gli utenti, quando richiedono un’inference, possono pagare di più per aumentare il livello di sicurezza e decentralizzazione dell’inference.
Perché è così e come si collega all’approccio basato su cryptoeconomics per la validazione? Quando un utente vuole aumentare il livello di sicurezza, in realtà sta pagando di più per consentire a più subgraphs (quindi più nodi) di eseguire l’inference sul suo prompt. Ciò significa che più nodi eseguiranno l’inference sugli stessi strati, e il loro risultato sarà confrontato tra loro dai nodi validatori. Questo non solo aumenta la sicurezza ma è anche veloce perché ciò che i validatori devono verificare è l’uguaglianza dei output tensors.
Facciamo un esempio per chiarire questo punto.
L’utente seleziona un livello di sicurezza di 3, il che significa che 3 subgraphs saranno scelti per eseguire l’inference. Questi subgraphs avranno la stessa partizione, il che significa che il numero di nodi (N) e il numero di strati per nodo (M) saranno gli stessi. Per questo esempio, impostiamo:
Ciò significa che avremo 3 subgraphs con 5 nodi ciascuno che calcoleranno 10 strati ciascuno. Il numero di nodi definisce anche la profondità del nostro subgraph, ossia il numero di “passaggi di inference” che dobbiamo eseguire per ottenere l’output finale. Definiremo anche con la notazione Ixy il y-esimo nodo del x-esimo subgraph che sta attualmente eseguendo l’inference. Questo sarà utile per spiegare come i processi di inference e validazione lavorano insieme.
Passo 1:
I nodi I11, I21, I31 stanno attualmente eseguendo l’inference sui loro 10 strati usando il prompt di input. Tutti restituiscono lo stesso vettore di risultato [a, b, c]; questo output viene inviato ai nodi successivi dell’anello di inference e ai nodi validatori.
Passo 2:
I nodi I12, I22, I32 stanno eseguendo l’inference sui loro 10 strati usando il vettore di risultato dei primi nodi. Tutti restituiscono lo stesso vettore di risultato [d, e, f]; questo output viene inviato ai nodi successivi dell’anello di inference e ai nodi validatori.
Passo N — 1:
I nodi I1N-1, I2N-1, I3N-1 stanno eseguendo l’inference sui loro 10 strati usando il vettore di risultato dei primi nodi. Il nodo I2N-1 restituisce un risultato diverso dagli altri due nodi.
Passo N:
I nodi finali dell’anello eseguono l’ultima parte di inference, ma ovviamente, a causa del risultato errato del nodo I2N-1, il subgraph 2 sta producendo un’inference diversa (o “sbagliata”).
I validatori, dopo aver ricevuto tutti i risultati intermedi di inference (o durante il processo, ancora da definire), eseguono un controllo di uguaglianza vettoriale tra tutti i diversi livelli. Scoprono che il nodo I2N-1 è l’unico che ha restituito un output diverso dagli altri nodi del suo livello, quindi subisce lo slashing. Il risultato corretto (output dei subgraphs 1 e 3) viene inviato all’utente.
Perché questo aumenta la sicurezza? Perché la probabilità che più nodi vengano selezionati allo stesso livello, per la stessa richiesta di inference e con l’intento di deviare, è estremamente bassa. Questo è dovuto al fatto che questo tipo di modello assomiglia al modello del formaggio svizzero: avere più subgraphs con diversi strati è come avere più fette di formaggio svizzero sovrapposte; per ottenere il risultato finale di restituire un risultato malevolo o errato all’utente è come cercare di passare attraverso tutti i buchi delle fette di formaggio contemporaneamente fino a raggiungere il fondo.
Dal momento che questo tipo di modello di sicurezza ci permette di trovare facilmente i nodi malevoli, combinando questo con il fatto che i nodi vengono penalizzati per agire “diversamente” dagli altri nodi e con il fatto che i nodi validatori sono anch’essi soggetti al loro algoritmo di consenso con penalità, possiamo raggiungere un livello rilevante di sicurezza senza sacrificare le prestazioni e senza implementare algoritmi crittografici complessi che costerebbero molto in termini di denaro e tempo.
Latenza (comunicazione inter-dispositivo)
Come menzionato in precedenza, la latency è una metrica chiave. Per ottenere una comunicazione inter-dispositivo efficiente e ottimizzare il DCI Network, vogliamo concentrarci sulle seguenti strategie chiave.
Quando creiamo i subgraphs (anelli), dobbiamo assicurarci che i nodi vicini tra loro siano fisicamente (o logicamente) vicini in termini di latenza di rete. Questo riduce i ritardi di comunicazione tra i nodi mentre i risultati dell’inference vengono passati lungo l’anello.
Questa ottimizzazione può essere raggiunta usando metriche di distanza di rete (come latency o bandwidth) quando si formano i subgraphs. Questo è anche noto come network proximity awareness.
Il primo passo per creare un sistema consapevole della prossimità di rete è misurare la latency e la bandwidth tra i nodi. Ci sono due approcci principali per farlo:
Una volta raccolti i dati, procediamo con la creazione di una tabella di prossimità, dove ogni nodo memorizza la sua latenza stimata rispetto agli altri nodi. Questa tabella può (e deve) essere aggiornata con nuove misurazioni.
Questa matrice contiene la latenza pairwise tra tutti i peer del nodo:
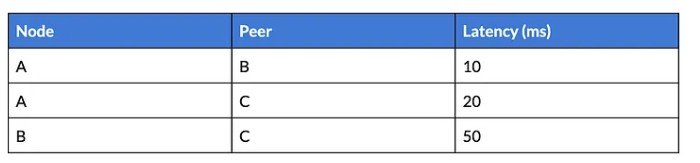
Questa matrice viene distribuita tra i nodi senza coordinamento centrale e ogni nodo può accedervi per scegliere vicini con bassa latenza per formare la topologia ad anello. Costruire questa matrice è cruciale quando si implementa il nostro algoritmo di formazione dell’anello basato su una delle strategie proposte sopra.
Oltre a considerare la latency, è importante ovviamente tenere conto della bandwidth e delle risorse computazionali: i nodi con maggiore bandwidth e risorse computazionali più potenti possono essere prioritizzati per strati con calcoli più pesanti o trasferimenti di dati intermedi più grandi. Questo richiede la costruzione di una metrica composita che combini sia latency che bandwidth nella matrice di prossimità.
Dobbiamo impostare una soglia di bandwidth (bandwidth thresholding) per selezionare i vicini, assicurando che i nodi con bandwidth insufficiente non vengano scelti per compiti di inference ad alto throughput. Questo significa creare un punteggio composito che pesi sia la latency che la bandwidth per ogni coppia di nodi.
Calcoliamo tale punteggio con la seguente formula:
score_ij = αlatency_ij + β*(1/bandwidth_ij)*
Dove α e β sono i pesi che bilanciano l’importanza della latency rispetto alla bandwidth.
Costruire una matrice di prossimità del genere è un compito comune nei sistemi su larga scala con molti nodi. Fortunatamente, ci sono diversi approcci distribuiti che possono aiutarci a raggiungere questo obiettivo:
Chord organizza i nodi in un anello logico basato sui loro identificatori hashati (node IDs). Ogni nodo mantiene una finger table con puntatori a nodi a distanze crescenti nell’anello, il che consente ricerche efficienti con complessità O(log N). Un nodo conosce anche il suo successore immediato (il nodo successivo nell’anello) e il suo predecessore (il nodo precedente), garantendo che i dati possano essere instradati attraverso l’anello in modo efficiente.
L’implementazione “predefinita” di Chord usa la distanza ID per calcolare successori e predecessori. Dobbiamo modificare questa logica di instradamento per tenere conto sia della prossimità (basata su latency e bandwidth) che della distanza ID.
Chord è tollerante ai guasti e gestisce l’ingresso, l’uscita e i guasti dei nodi regolando le finger tables e i puntatori ai successori. Con la consapevolezza della prossimità:
Per massimizzare le prestazioni, il DCI Network deve essere testato in diverse condizioni (es. bassa bandwidth, alta latency, guasti dei nodi, ecc.) per garantire che questa strategia di instradamento consapevole della prossimità migliori costantemente le prestazioni. Inoltre, dobbiamo sperimentare con diversi valori di α e β per ottimizzare per bassa latency o alta bandwidth, a seconda della natura del compito di inference del modello AI corrente.
La Selective Participation è una strategia in cui i nodi in una rete distribuita si auto-selezionano o vengono assegnati a specifici tipi di compiti di inference in base alle loro risorse computazionali, in particolare in termini di Teraflops (TFLOPS).
Un Teraflop si riferisce alla capacità di un processore di calcolare un trilione di operazioni in virgola mobile al secondo. Questo significa che quando un dispositivo ha “8 TFLOPS”, intendiamo che la sua configurazione di processore può gestire in media 8 trilioni di operazioni in virgola mobile al secondo. A differenza dei gigahertz (GHz) — che misurano la velocità di clock di un processore, un TFLOP è una misura matematica diretta delle prestazioni di un computer.
I nodi possono essere categorizzati in diversi livelli basati sulla loro capacità computazionale; ogni categoria corrisponde alla complessità e alla dimensione dei modelli AI che i nodi sono in grado di elaborare. Un esempio di tale categorizzazione (da definire) potrebbe essere:
Categorizzando i nodi in questo modo, la rete garantisce che i nodi con risorse computazionali sufficienti gestiscano i modelli AI più esigenti, mentre i nodi meno potenti si concentrano su modelli leggeri. Questo crea anche un’opportunità per le persone che partecipano alla rete usando un dispositivo mobile (come il loro smartphone), consentendo a questi dispositivi meno performanti di partecipare all’inference di modelli più piccoli.
Utilizzando una vera rete di inference decentralizzata, consentiamo ai compiti AI di essere eseguiti attraverso una rete di nodi, dove il calcolo è distribuito dinamicamente ed efficientemente, mantenendo al contempo un alto livello di sicurezza e ricompensando gli utenti per la condivisione della loro potenza computazionale.
Infatti, il nostro approccio:
Questa nuova rete decentralizzata non solo farà avanzare la tecnologia AI, ma darà anche potere a individui e organizzazioni di partecipare, beneficiare e contribuire all’ecosistema AI come mai prima d’ora.
La nostra rete ha anche profonde implicazioni per l’ecosistema web3. Fondendo l’AI con i principi della Blockchain, in particolare attraverso l’incentivazione, creiamo un sistema autosostenibile che ricompensa gli utenti per il contributo della loro potenza computazionale.
La nostra rete non solo compensa gli utenti, ma crea anche indirettamente un mercato dove la potenza computazionale viene commoditizzata. Non la potenza computazionale di fascia alta e costosa, ma quella quotidiana, per lo più inutilizzata e “sprecata”.
Il concetto di sfruttare la potenza computazionale sprecata è vecchio quanto internet. Uno dei primi esempi, il progetto Condor (ora HTCondor), è iniziato nel 1988. Nel 1993 Scott Fields scrisse un campionatore di ricerca chiamato “Hunting for wasted computing power”, con l’obiettivo di mettere al lavoro i PC inattivi.
In tale campionatore di ricerca c’è una frase che vorremmo citare: “La filosofia qui è che vorremmo incoraggiarvi a usare quanti più cicli possibile e a fare progetti di ricerca che possano durare settimane o mesi. Ma vogliamo proteggere i proprietari, che siano o meno utenti intensivi”.
Possiamo suddividere questa citazione nelle sue parti:
Nel contesto della nostra rete, questa frase può essere riscritta come: “La nostra filosofia è incoraggiare la piena utilizzazione delle risorse computazionali disponibili, dando agli utenti il potere di contribuire ai compiti di inference AI. Tuttavia, rimaniamo impegnati a proteggere gli interessi dei proprietari delle risorse, garantendo che siano equamente compensati per la loro partecipazione”.
Risorse
Questo articolo dallo studio di diversi progetti, paper e protocolli di straordinari ricercatori e sviluppatori di AI e web3.
Ti è piaciuto questo articolo? Ne stiamo discutendo nella nostra Community su LinkedIn, Facebook e Instagram. Seguici anche su Google News, per ricevere aggiornamenti quotidiani sulla sicurezza informatica o Scrivici se desideri segnalarci notizie, approfondimenti o contributi da pubblicare.

 Cybercrime
Cybercrime Innovazione
Innovazione Cybercrime
Cybercrime Vulnerabilità
Vulnerabilità Innovazione
Innovazione